
You know all about hashes in cybersecurity and how to decode Base64; you’re likely also familiar with steganography, and maybe you can even recite the history of cybersecurity and the development of EDR. But how about explaining the malicious use of shellcode? You know it has nothing to do with shell scripts or shell scripting languages like Bash, but can you hold your own talking about what shellcode really is, and why it’s such a great tool for attackers?

Not sure? No problem. We’ve got just the post for you. In the next ten minutes, we’ll take you through the basics of shellcode, what it is, how it works and how hackers use it as malicious input.
What is ShellCode?
We know shellcode has nothing to do with shell scripting, so why the name? The term “shellcode” was historically used to describe code executed by a target program due to a vulnerability exploit and used to open a remote shell – that is, an instance of a command line interpreter – so that an attacker could use that shell to further interact with the victim’s system. It usually only takes a few lines of code to spawn a new shell process, so popping shells is a very lightweight, efficient means of attack, so long as we can provide the right input to a target program.
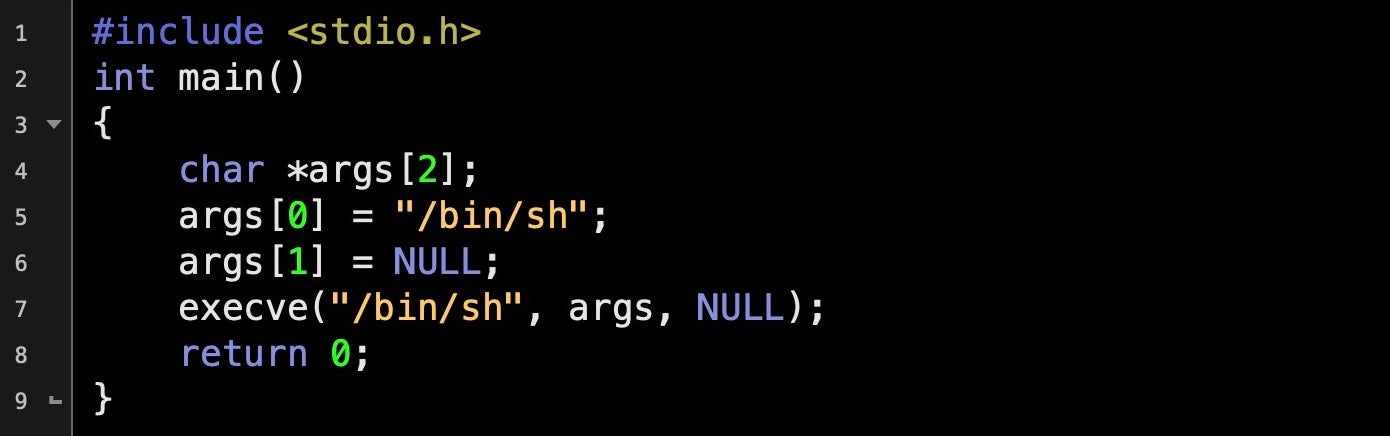
Standard C code like that above will pop a shell. You can compile and run it simply enough in an editor like Geany. It’s possible to turn small programs such as the one above into input strings that can be supplied to a vulnerable program to achieve the same effect. The bonus for attackers is that if your target program is running with elevated privileges, your newly spawned shell will inherit those same privileges, too.
Creating a shellcode string from ordinary code like that above requires using a disassembler to reveal the assembly “underneath” the compiled C. We can do that in any disassembler such as IDA, Ghidra, OllyDbg, Radare2 or otool on macOS. Here’s what the program above looks like in a disassembler.
The opcodes that we would need to create our shellcode are highighted in red. To the right of those are the same instructions in the more human-readable assembly language.
Once we have our opcodes, we need to put them into a format that can be used as string input to another program. This involves concatenating the opcodes into a string and prepending each hex byte with x to produce a string with the following format:
x55x48x89xe5x48x83xecx30x31xc0x89xc2x48x8dx75xe0x48x8bx3bx0dxe9x...
How To Create Shellcode?
So far so good, but there’s a problem. Our shellcode instructions are not allowed to contain zeroes, as any zero character in our input string will be interpreted by the target program as a null-terminator character, and the rest of the shellcode will consequently be discarded. As we can see, our program above has a great many null bytes.
In order to solve this problem and create well-formed shellcode, we need to replace any instructions containing null bytes with other instructions. Doing so is much easier if we code directly in an assembly language like NASM rather than starting in a language like C and extracting the assembly. Let’s look at another example that has been specially-crafted to avoid the null-bytes problem. Below is the disassembly for a similar problem that also pops a shell using execve(), but the assembly is much smaller and more efficient than before.
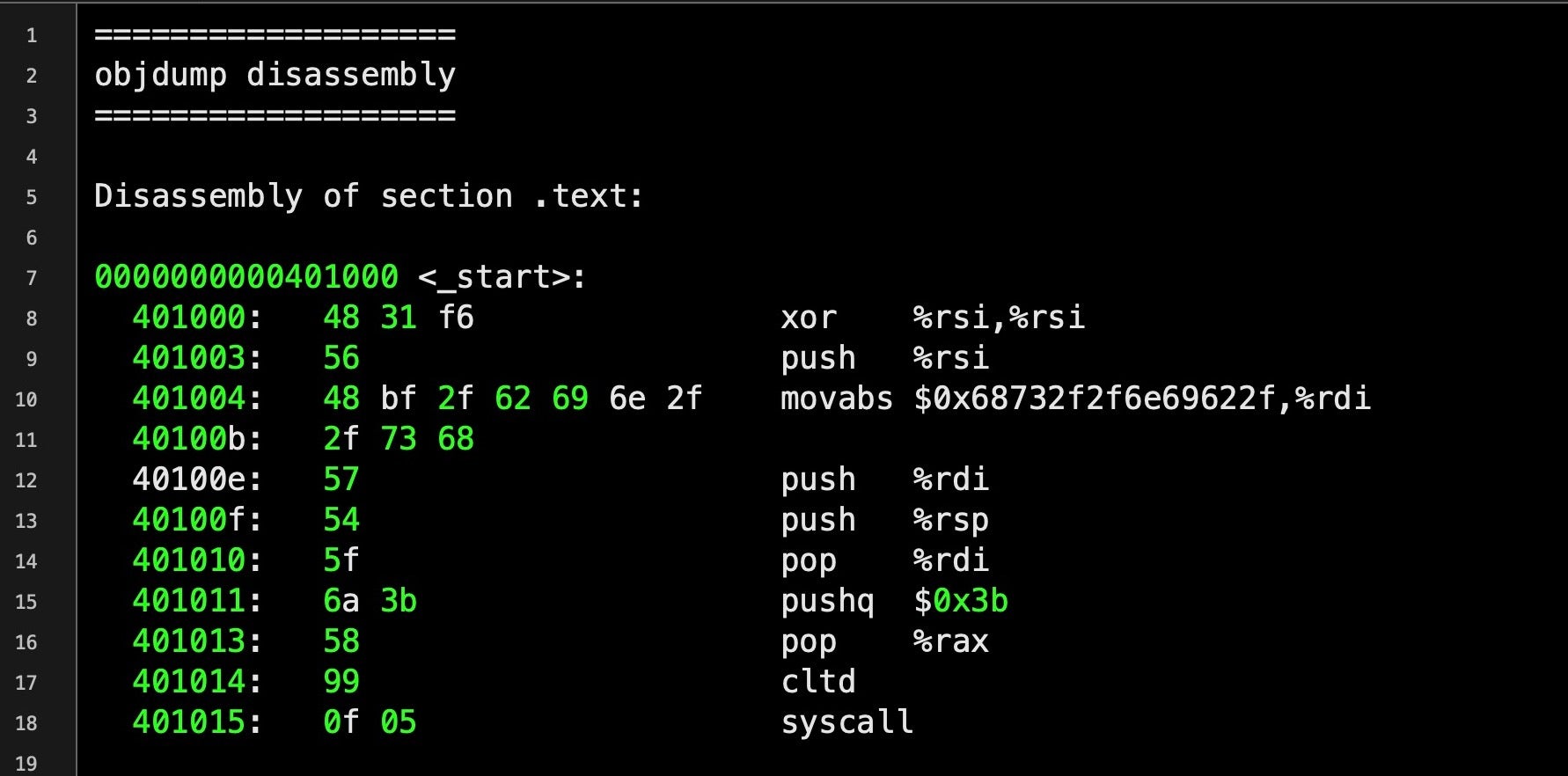
Notice at line 8 the hexadecimal 48 31 f6, which represents the instructions for the following assembly:
xor %rsi, %rsiThe use of XOR here is an example of sidestepping the restriction of not being able to use zeroes we mentioned above. This particular program needs to push the integer 0 onto the stack. To do so, it first loads 0 into the CPU’s %rsi register. The natural way to do that would be:
mov $0x0, %rsiBut as we can see if we input that into an online disassembler, that produces raw hex with zeroes in the instruction operand.
4889342500000000We can get around that by xoring the value of %rsi with itself. When both input values of XOR are the same, the result will be zero, but the instruction doesn’t require any zeroes in the raw hex.
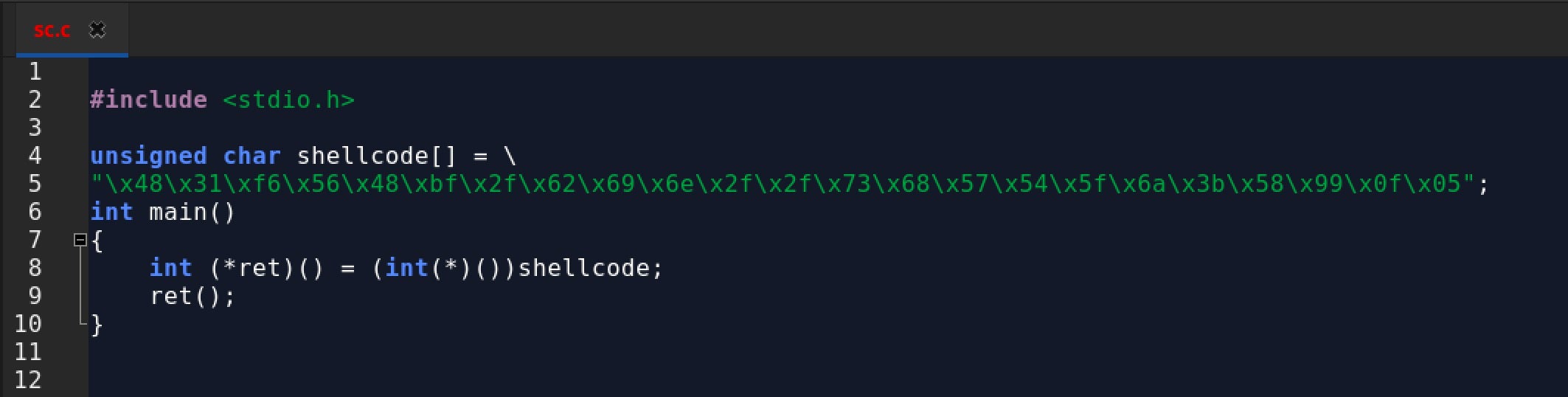
We can now produce a well-formed shellcode string that contains our complete program:
x48x31xf6x56x48xbfx2fx62x69x6ex2fx2fx73x68x57x54x5fx6ax3bx58x99x0fx05
Let’s create a program that executes our shellcode to see that it works:
Finding Vulnerable Programs
So now we have some shellcode and a proof of concept, but finding vulnerable programs that we can feed our shellcode to isn’t a simple matter. One way is through reverse engineering a program, fuzzing and experimenting in the hope of finding a target program that mishandles certain edge cases of input data. In cases where the program code mishandles some unexpected form of input, this can sometimes be used to alter the program execution flow and either make it crash or allow us to run our own instructions delivered by the shellcode. One common programming error that can often be used to achieve this is a buffer overflow.
What is a Buffer Overflow?
A buffer overflow occurs when a program writes data into memory that is larger than the area of memory, the buffer, the program has reserved for it, thus overwriting some unrelated program data. This is a programming error, as code should always check first that the length of any input data will not exceed the size of the buffer that’s been allocated. When this happens the program may crash, but specially-crafted input like our shellcode may instead allow an attacker to execute their own code. Here’s a simple example of a buffer overflow waiting to happen.
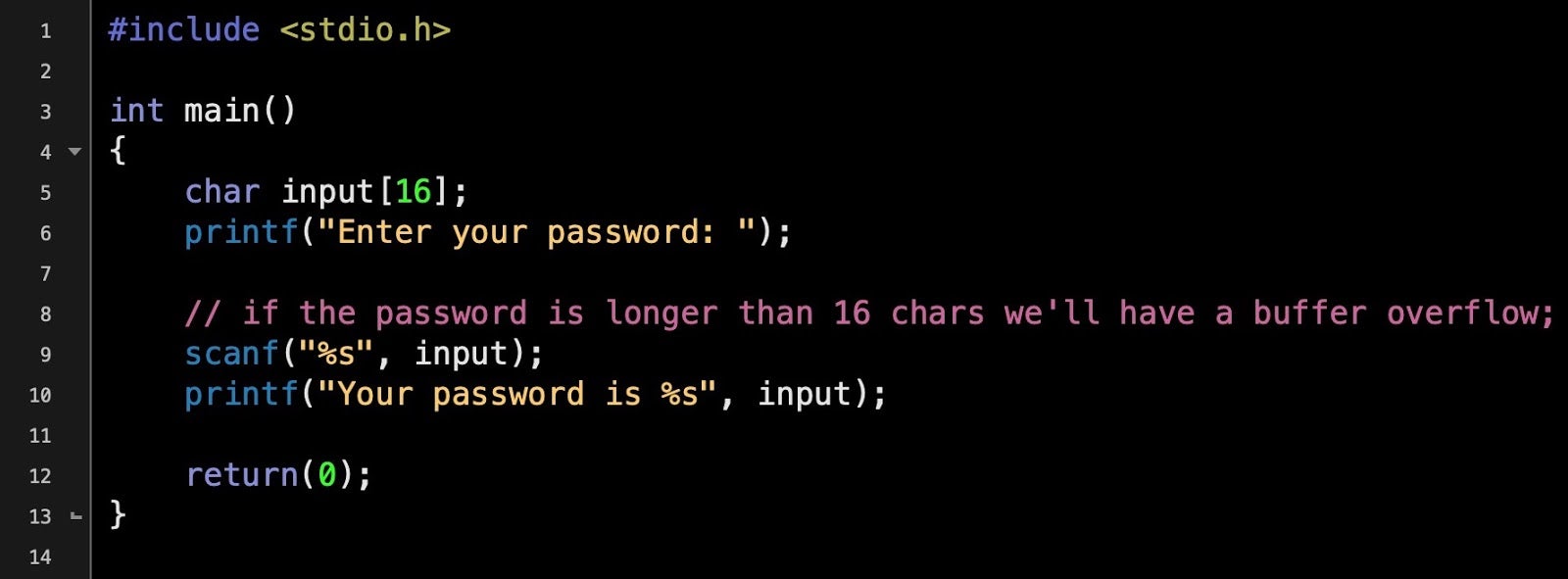
The program reserves 16 bytes of memory for the input, but the size of the input is never checked. If the user enters a string longer than 16 bytes, the data will overwrite adjacent memory – a buffer overflow. The image below shows what happens if you try to execute the above program and supply it with input greater than 16 bytes:
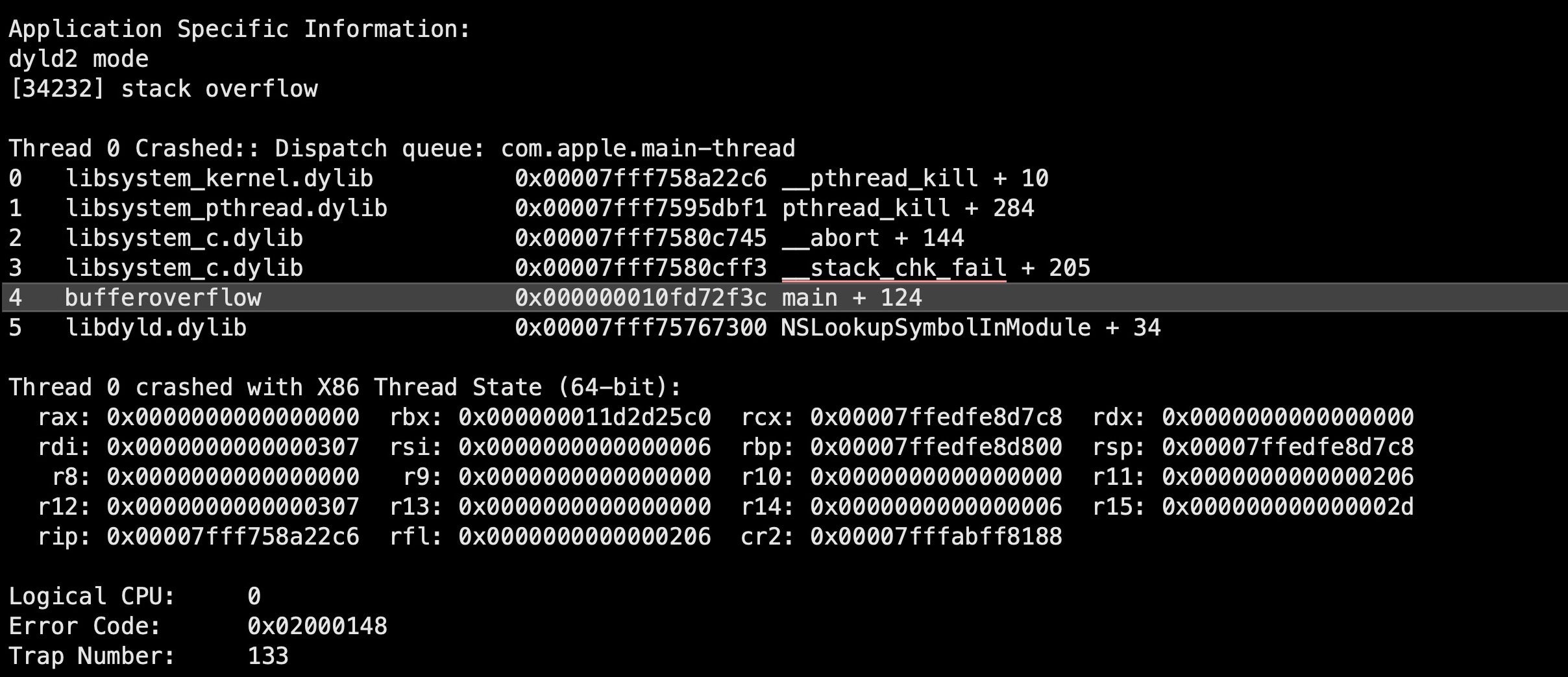
However, just causing a buffer overflow in a program isn’t on its own much use to attackers, unless all they want to do is bring the application to a crashing halt. While that would represent a win of sorts for attackers whose objective is some kind of denial of service attack, the greater prize in most cases is not just causing the overflow but using it as a means to take control of execution.
Taking control of execution is a complex matter, but essentially involves determining precisely how much data we need to write to overflow the buffer sufficiently to ensure our shellcode is executed. This requires writing our own code both at a given address and ensuring that the target program’s current function – that block of code which is handling our shellcode string and deciding what should happen next – returns to the address where our exploit code is waiting. If we can control that, we have a good chance of getting our exploit to successfully execute.
Shellcode & Exploitation Kits
While writing your own shellcode is a task that requires a certain amount of skill, including knowledge of assembly, attackers have a variety of tools available to help them out. There are publicly available post exploitation kits like Metasploit and PowerSploit that offer things like encoders to help generate compliant shellcode, tools to create payloads and functions that can inject shellcode directly into processes.
On Linux and macOS, even a simple bash post-exploit kit like Bashark will offer a function to execute shellcode.

Examples of pre-made shellcode can readily be found across the internet, including in resources for penetration testers and red teamers like the Exploit Database, although real-world attacks will often require some degree of customization to ensure the shellcode is suited to the target program, execution environment and attacker objectives.
Protecting Against Shellcode
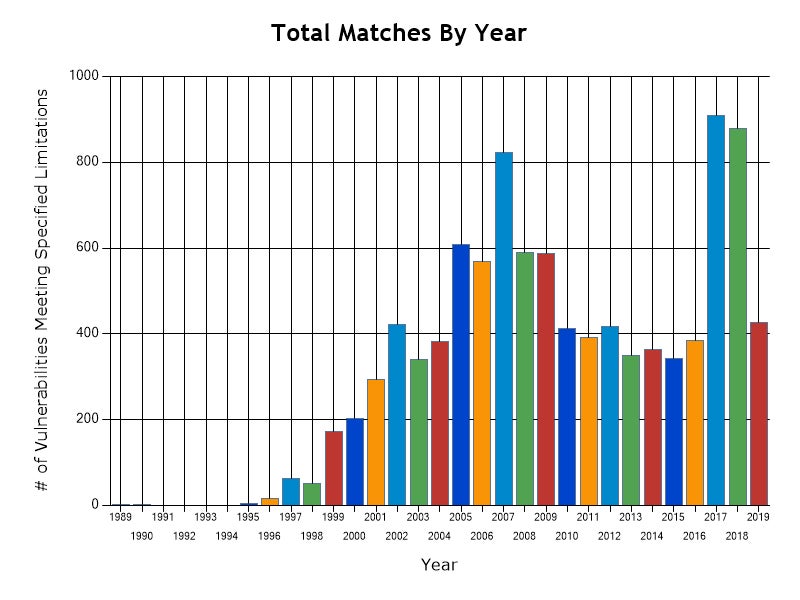
You would think that input mishandling resulting in buffer overflows, which have been known about for decades, would be becoming rarer, but in fact the opposite is true. Statistics from the CVE database at NIST show that vulnerabilities caused by buffer overflows increased dramatically during 2017 and 2018. The number known for this year is already higher than every year from 2010 to 2016, and we still have almost 5 months of the year left to go.
Clearly, there’s a lot of unsafe code out there, and the only real way you can protect yourself from exploits that inject shellcode into vulnerable programs is with a multi-layered security solution that can not only use Firewall or Device controls to protect your software stack from unwanted connections, but also that uses static and behavioral AI to catch malicious activity both before and on execution. With a comprehensive security solution that uses machine learning to identify malicious behavior, attacks by shellcode are seen just like any other attack and stopped before they can do any damage.
Conclusion
In this post, we’ve taken a look at what shellcode is and how hackers can use it as malicious input to exploit vulnerabilities in legitimate programs. Despite the long history of the dangers of buffer overflows, even today we see an increasing number of CVEs being attributed to this vector. Looking on the bright side, attacks that utilize shellcode can be stopped with a good security solution. On top of that, if you find yourself in the midst of a thread or a chat concerning shellcode and malicious input, you should now be able to participate and see what more you can learn from, or share with, others!

