History will look back on our time as the beginning of the artificial intelligence revolution. In 2017, artificial intelligences are beating us at Go, translating and inventing their own languages, helping us decide what to buy, writing for us, and composing music. Neural networks can even be used for image compression! As you might expect, the endpoint security industry is benefiting greatly from AI as we are using it for everything, from detecting threats to unusual network activity.
However, sometimes the problem with a complex, new technology, apart from actually inventing and building it, is figuring out how to explain it to customers — how does it work and why is it valuable. Unfortunately, a lot of messaging tends to either emphasize trivial and unimportant details or is too vague to give any insight.
In this post, I will cut through the noise and explain what’s most important in machine learning and for security products in general.
The Secret Sauce Isn’t the Algorithm, it’s the Data.
A lot of vendors focus on the algorithm. Everyone wants to say they use deep learning and neural networks. I think this is because both of these sound really cool, and neural networks get a lot of attention because they invoke mental images of digital brains. However, once you know how neural networks work, they’re a lot less magical. You can check out my demystification of random forests in a previous post.

The specific machine learning algorithm used is irrelevant. It’s like bragging about using certain software engineering design patterns, sorting algorithms, or using functional languages. The nitty gritty details of how code is written is less important than what the code actually does, in the same way that any machine learning algorithm is good if it produces useful, efficient models.
The most important factor in making a useful model is the quality of the data. You can have machine learning without sophisticated algorithms, but not without good data. For malware, this means having a diverse and representative set of both malicious and benign files users are likely to experience. This is much easier said than done. At SentinelOne we expend a lot of time, effort, and ingenuity on carefully expanding and curating our data sets to be as large, diverse, and relevant as possible. Malware is always changing, and we’re always updating our data set with fresh malware.
For a further explanation on the usefulness of data and why it’s a good idea to stick to the simplest model possible, see Daniel Tunkelang’s answer on Quora to the question What should everyone know about machine learning?.
Understanding the Numbers
So what does it even mean to say that a model is useful?
There are many ways to quantify usefulness, but the three numbers I look at the most are precision, recall, and accuracy.
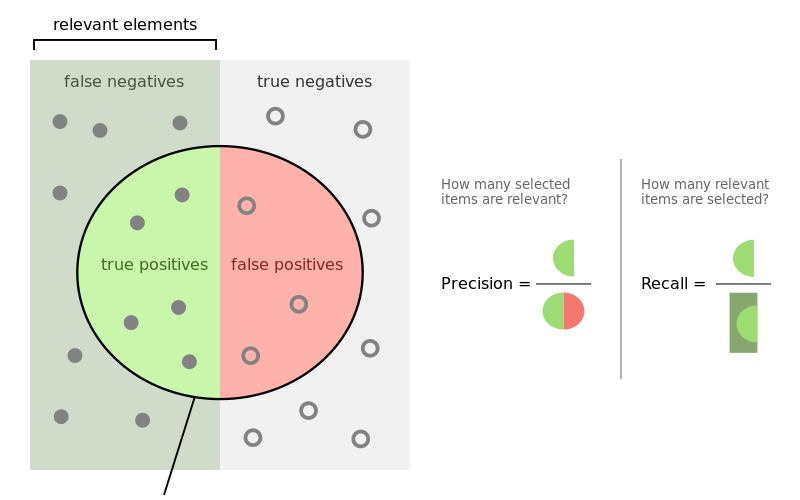
Precision is the model’s false positive rate. It’s the number of true positives divided by the total number of samples selected by the model and it is super important to keep this rate low for an endpoint security product as I have discussed previously.
Recall tells you how much of the bad stuff the model detects. It’s the number of true positives divided by the total number of samples which should’ve been selected. You can think of this as efficacy of detection. Increasing precision usually comes at the cost of recall. You can see this trade off quite clearly in a receiver operating characteristic plot.
Accuracy blends together precision and recall. It’s the total number of correct hits (true positives and true negatives) divided by the total number of samples. The more accurate the model, the more useful it is.
The Numbers Don’t Really Matter.
Now that you understand the numbers behind model performance and that performance is more important than the algorithm, it’s time for one last curve ball: the numbers don’t really matter either. The reason is simple: the model is ultimately only a single component of a larger system. For example, there are several good heuristics to determine if a file is benign, such as if a file is signed by a trusted third party such as Microsoft or if the file’s hash is found on many machines across multiple customers. This means it is likely not malicious and could, perhaps, be evaluated differently with a much more conservative model.
Note: Not all signatures should be treated equally. We’ve seen malware signed by trusted parties before with the recent CCleaner malware.
Here’s another secret: it’s really easy to build a malware detection model with ~95% accuracy just by pulling a few libraries off the shelf and writing a few dozen lines of Python. This assumes you have a decent data set, of course. It takes much more time and skill to improve accuracy to 99.9%, and getting to 99.99% accuracy is FAR more difficult. But even with 99.99% accuracy, that’s still one false positive in every 10,000 files, which is abysmal. My Windows machine has 40,291 PE files, and 99.99% accuracy would, on average, result in fourbenign executables getting deleted. This could break important programs or even the operating system itself.
The impossibility of 100% accuracy is why it’s necessary to surround the model with other layers, such as the signature or popularity checks mentioned earlier. And these additional layers are why even model metrics are really only useful internally to researchers like me who are always trying to make better models. As a customer, evaluating the performance of a security product must be done holistically.
So What Really Matters?
So how do you evaluate a security product holistically? You might think it’s by measuring detection rates, but you probably don’t have a representative test set of recent, diverse, live, and relevant malware. Even if you had a good test set, malware is always changing and you need to know if the product vendor responds quickly to new threats. In other words, you don’t just want a product with great detection; you want a product with great detection that’s always improving and keeping up with a constantly evolving threat landscape.
This is, of course, not to say that machine learning isn’t useful. They’re both essential for us in maintaining detection improvement velocity. For example, our behavioral engine detects malware by a combination of heuristics and by modeling how good and malicious apps behave. This is a vast improvement over traditional static byte signatures because byte signatures are easily broken with polymorphism and modeling malicious behavior allows us to detect completely novel threats. Additionally, machine learning allows us to automate static analysis and detection by leveraging lots of data and excellent feature engineering driven by a deep understanding of how malware looks.
In summary, don’t be distracted by talk about specific algorithms. While machine learning and AI is really useful, it doesn’t really matter if a product uses a neural network, stochastic gradient descent, adaptive boosted random forests, or whatever. Instead, focus on what really matters: threat response time. At SentinelOne, we’re confident we can keep up with new threats and offer a ransomware protection warranty which provides customers with financial support of $1,000 per endpoint, or up to $1 million per company.
Want to learn how SentinelOne can help keep you secure?
Request a Demo today and see us live!
Like our content?
Subscribe to our blog above and get content delivered straight to your inbox or follow us on LinkedIn, Twitter, and Facebook to stay up to date on the latest news in cybersecurity!

