
Who is responsible for the security of your open source software dependencies, and what are the risks? Find out the surprising answer here.
A couple of years back when the Equifax breach occurred, there was a lot of talk about open source code and how secure it is, or isn’t. The issue hasn’t gone away, either, with both real and imagined hacks frighteningly easy to pull off. A recent report suggests that more than 60 of the Fortune 100 companies may still be using code containing the same vulnerability that led to the Equifax breach. In this post, we take a look at open source security and how it can impact the enterprise.

Dependencies Everywhere
The Equifax breach was a result of a bug in Apache Struts, but that was neither unique nor extraordinary. OpenSSL, an open source implementation of SSL and TLS used in web servers, contained the heartbleed flaw that affected at least half a million websites. Heartbleed didn’t just affect servers, but also applications that relied on the affected versions of OpenSSL, including offerings from Oracle, McAfee and VMware.
By one estimate, over 5000 vulnerabilities have been discovered in open source software since 2017.
If you’re not actually a developer, you might be surprised at just how much of your organization’s software relies on open source components. Using community-produced software saves development time and cost, and allows organizations to essentially outsource maintenance to a worldwide community of organizations and volunteer developers. These wins have led to suggestions that there’s more open source code than proprietary code in the majority of organizational codebases, with on average a single codebase containing over 250 open source components. From package managers like the node.js npm and Python’s PyPI and pip, to Rubygems and plug-ins for build tools like Maven or development tools like Visual Studio, free, shared code is everywhere.
How Many Eyes, Really?
As far as security is concerned, the big win in using open source software is supposed to be transparency. Open source projects mean that everyone and anyone can inspect the source code. At least in theory, the fact that there are “many eyes” on the code should mean that bugs and flaws are spotted and fixed quickly.
But there are two “gotchas” about the “many eyes” theory. First, by far the majority of projects are maintained by either a solitary developer or a small team of volunteers. How often they actually have the time and resources to look at and update their code is a complete unknown, and certainly not subject to any formal process. In other cases, the software may not be maintained at all. Those who create and contribute free software are under no obligation to maintain it. Indeed, most such software usually comes with some kind of “AS IS” disclaimer:
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE
The reverse side of that disclaimer is if the developer isn’t responsible for the code, then it is clearly the responsibility of the consumer to make sure the code is safe and “fit for purpose”.
Second, even in the case of a large project with many volunteers, the reality is that when there are “many eyes” it’s easy for everyone to think someone else is looking. That no one may in fact be looking was evident with the Heartbleed bug, which was introduced to the public repository in 2012 and wasn’t spotted until April 2014.
Owning Your Sources
There’s no doubt that open source code is both a boon for businesses and consumers. But it’s important to recognize that free code still comes at a cost: the cost of responsibility. It is up to businesses to ensure that their codebase is secure because it is the business that will bear the brunt of any losses, both financial and reputational.
In practical terms, that means you need visibility both into what code you are dependent on and what that code is doing on your system. There are tools that can be used to audit open source code for known vulnerabilities and databases that can be manually searched.

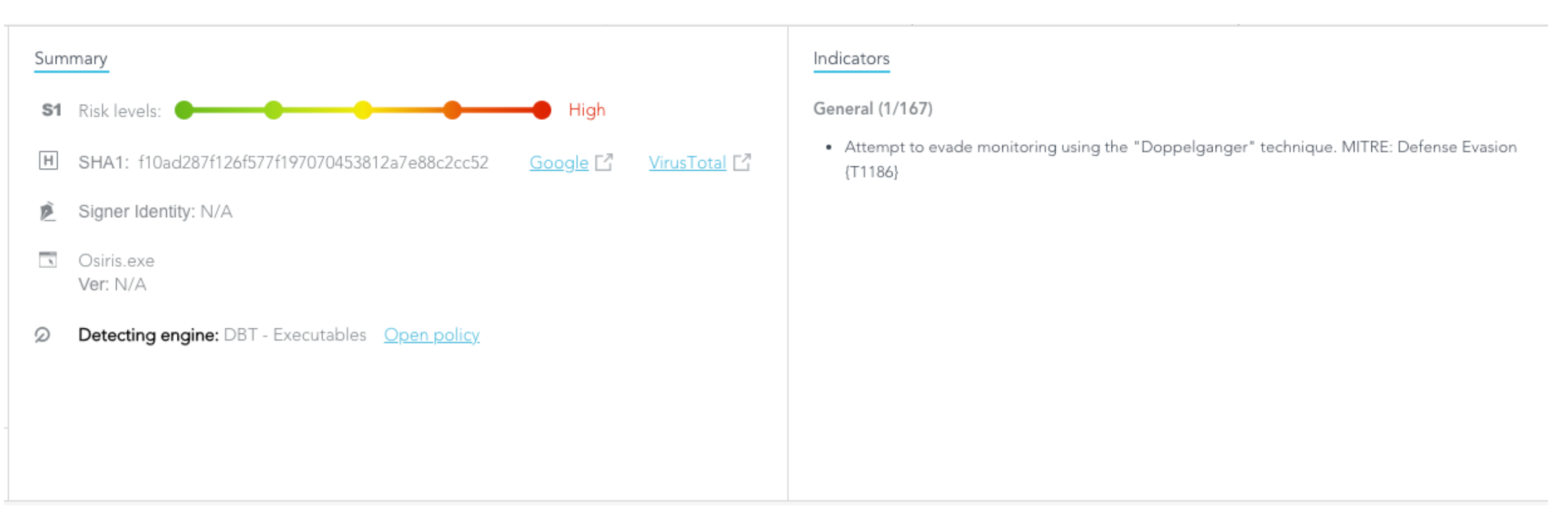
However, you also need automated security software capable of detecting behavioural anomalies and linking vulnerabilities back to known tactics and techniques, such as those catalogued by the MITRE ATT&CK framework. Being able to see the attack storyline and putting it into context helps you to understand how the attack occurred and to close down vulnerable gaps across your entire network.
Conclusion
Open source code is just another part of your supply chain, and an attack that leverages vulnerabilities in an open source library, package or application is just another kind of supply-chain attack. Therefore, no matter what dependencies you have, whether they are open-source or proprietary, you need to treat all code on your network with the same suspicion and monitor not just where it came from but also what it is doing. An EPP and EDR solution like SentinelOne can help protect your organization from issues arising from bad code, whatever its source.

