
On this post, we will cover the incident response process of an imaginary e-commerce portal – The first segment will focus on the preparation phase, the second on the technical investigation and the third and last section will be an incident closure. If you are an experienced user you may find some new ideas to inform your practice, and if you are a newcomer the posts will serve as a “101” with some good references.
Preparation Phase
When facing a potential breach, two battles are being fought: the first one is against the adversary and the second one is against time. The idea behind the preparation phase is simple: save as much time as possible. This can be accomplished by anticipating certain tasks. For example, having procedures, tools and contacts ready when they are needed is a very good idea. If we take a look at how IT Security-wise companies work, we often find a common thread: they do their homework, and they do it well.
The following areas will be discussed:
- Knowledge of the infrastructure and stakeholders
- Weak points
- Emergency Plan
- Context and news
- Anomalies and Baseline
These are the objects which compose our architecture:
- Firewalls (FW1, FW2)
- IPS (IPS1)
- WAF (WAF1)
- Load Balancers (LB1, LB2)
- Front End Layer (FEServ1, FEServ2, FEServ3)
- Back End Layer (BEServ1, BEServ2, BEServ3)
- Persistence Layer (DB1, DB2, LDAP1)
- API Gateway etc. (EBUS1)
Knowledge of the Infrastructure and Stakeholders
Firstly, we want to have a clear picture of what we are protecting; thus, having a discussion with upper management about what a workload represents for the organization is usually good practice. We can learn the business value from a quantitative perspective. A very basic example is how much the architecture is worth (e.g., the e-commerce portal is worth 1000$/hour in revenue). This helps us to decide the right thresholds in the event that we have to perform a lockdown (e.g., for a minor incident a traffic degradation on the cluster is acceptable, whereas for a major incident we might take more drastic decisions and lock down the infrastructure completely). It is also important to be conscious of what data is stored, transmitted or processed; for example, there might be valuable personal data in the persistence layer, and a leak there could impact the company in a catastrophic way from a legal and/or revenue perspective.
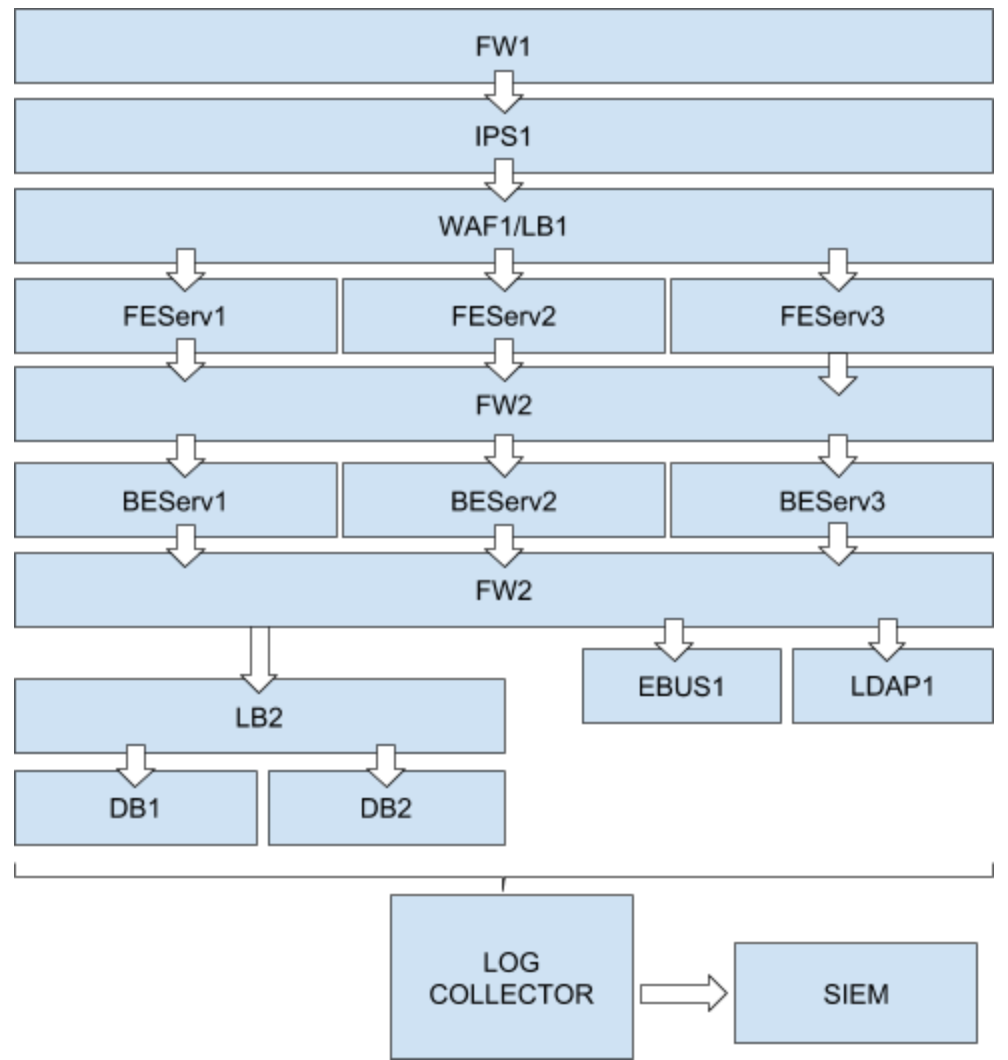
So what do we do when our spider-senses start tingling and we want to jump into an investigation? We take a deep breath, open our archive with the documents and notes and take a look at what we’ve got. If we have done our homework correctly, we should have a clear picture like the one below:
The investigation target is a Centos 7 Server placed in the Frontend Layer which has a PHP based technology stack built around an Nginx web server. Two other servers are performing the same function and traffic is balanced across them. They are in the same subnet and they may suffer from the same vulnerabilities. The target server has access to the Back End Layer which has access to the Enterprise Bus, LDAP and Database. The frontend layer is accessed from outside through Load Balancers with a WAF on top. The subnet is protected by a Network IPS and a Firewall. There is also an Inner Firewall controlling access to the various components of the backend. All the components send logs to the Enterprise Log Collector and the events are correlated by the SIEM.
As you can see it is not a very detailed picture, but very quickly you can gain an overview of the battlefield and where you may want to drill down.
A further step in the preparation phase is being ready to deepen the investigation and potentially ask for help in doing so. In fact, you may find yourself in need of assistance to analyze the behavior of certain components. Therefore, in the notes, we should also have escalation points for the key people who can help us in specialized areas. IT Security is never a one-man show.
For example, you may want these kind of contacts for various subject matter experts (SMEs):
- Snow – Senior Networking Engineer – [email protected] – +1234567890
- Duck – Senior System Engineer – d.duck@acme.com – +1234567890
- Skywalker – DevOps Lead – [email protected] – +456789410
- Mouse – Infrastructure and Operations Manager – [email protected] – +9876543210
Reaching out to SMEs can be vital in case you need to know the Load Balancing policies, analyze the code of the application, or have the whole Infrastructure Team help in case of a big issue.
Know the Weak Points
So far we have seen that a good knowledge of the components in our Architecture is crucial. Another important aspect is knowing the attack surface and its related risk. Having a proper vulnerability management platform will allow you to quickly search for vulnerabilities inherent to the architecture. This will be super handy both to aid in the investigation and to confirm possible attack vectors. For example, if the incident was triggered by a suspicious event like a bash command execution on your frontend, you can look into the vulnerability management platform, check the server, and if you see a bunch of remote code execution (RCEs) vulnerabilities, you may have found the entry point. Then looking at your logs may reveal what actions the malicious actor performed on your system.
The Devil Hides in the Anomalies…
Another important point is to detect anomalies. Having alerts coming from IPS/WAF etc. is good, but the devil is in the details. You may want to analyze the normal behavior of critical architectures and define a baseline, which is simply how the architecture is expected to work. Let me offer another example:
In our frontend server (FESrv1), suppose we have a folder (/media/static) which we use to deliver static assets like images or videos. In this case, we can put an alert in the SIEM for external access requesting a file which does not match your naming convention or extension. Often, it is a sweet spot for the attacker because it is a folder where the applications have “loose” permissions.
Another alert could be based on accessing the server outside of business hours. Why is a command being issued if nobody is working at that moment?
Of course, these are very basic and trivial examples, but the objective is to let you start thinking about them.
And Remember to Look Outside the Window…
It is also important that you keep an eye on the latest vulnerabilities or exploits being used in the wild. For example, when something like Drupageddon (SA-CORE-2014-005) emerges, you would want to consider whether you have Drupal running in any of your systems and take the appropriate remediation actions.
In order to keep up with evolving threats, you could build your own newsfeed to aggregate different sources such as security blogs, Reddit, CVE releases and so on. A good starting point is MorningStar Security News page.
So to wrap up this section, we now have:
- An overall architectural knowledge
- Contacts of important stakeholders that can help us
- Vulnerability map (to match what you see with what is doable from an attacker’s perspective)
- A baseline (what you should expect from you architecture) and if you are thorough you should also have rules that produce alerts for certain anomalies
- Awareness of the latest threats
Have an Emergency Plan Ready
To close our discussion of the preparation phase, we will need to have in place an action plan. A plan is always worthwhile even if you decide not to follow it thoroughly. It gives you direction and an overall objective when you are facing an emergency.
You may want to create a short outline of the main steps you need to take, for example:
- Confirm suspicious event
- Alert your escalation points based on the severity
- Contact EPP provider
- Contact SOC provider
- Alert Infrastructure Team that you are going to perform action X, Y, Z and ask for their cooperation
- Coordinate the restoration and the hotfix when the breach has been identified
- Understand the extent of the impact
- Coordinate with PR Department if needed
- Close the incident after restoration
- Keep monitoring the situation for other anomalies
- Write Report
You will typically be under pressure to decide and act quickly during a security incident, so a well-defined plan helps you to have a clear idea of each step you have to perform and who to involve.
Conclusion
The Preparation Phase is very important and will give you a clear direction to follow when dealing with stressful and delicate situations. In addition, just as surgeons have everything prepared before an operation, you will want to be similarly prepared and organized to minimize errors and avoid wasting time.
Coming Next: Investigation
In this article, we’ve discussed the preparation phase. In the next one, we will share the practical steps for technical incident response and investigation. We will see a set of actions and commands which will allow you to understand what is happening on a target machine (Linux Centos7 with a Nginx running).
Further Reading
If you want to dig deeper into the issues addressed in this article, I suggest the following readings:
Incident Response / Handling:
- NIST: Computer Security Incident Handling Guide
- SANS: Incident Handler’s Handbookawesome-incident-response
- awesome-incident-response: A curated list of tools for incident response
- CERT Societe Generale: IRM (Incident Response Methodologies)
- ENISA: Good Practice Guide for Incident Management
Incident Management Platform:
Some SIEM Ideas
- SANS: A Practical Application of SIM/SEM/SIEM Automating Threat Identification – How to use a SIEM effectively to identify and respond to security threats
- If you have and IDS or IPS you can use its alerts, otherwise ,you can build your own “IDS-like” set of alerts on the logger and correlate in the SIEM:
- https://rules.emergingthreats.net/open/suricata/rules/ (even simple IDS rules are worthwhile)
- https://github.com/PHPIDS/PHPIDS/blob/master/lib/IDS/default_filter.xml (you can even use some phpids rules to trigger events based on your access log)
BIO
G iammaria Urbisaglia is a professional IT Security Consultant, caffeine addict and night owl person (especially when it is about some hacking challenge) who likes fast, effective and down-to-earth solutions. He holds a MSc in cybersecurity and helps multinational and governmental organizations stay safe. If you want to get in touch just contact him through his LinkedIn page
iammaria Urbisaglia is a professional IT Security Consultant, caffeine addict and night owl person (especially when it is about some hacking challenge) who likes fast, effective and down-to-earth solutions. He holds a MSc in cybersecurity and helps multinational and governmental organizations stay safe. If you want to get in touch just contact him through his LinkedIn page

