
Microservices have gained such a level of popularity these days that they’re often touted as “the way” to build software. That’s all well and good, except there are a lot of microservice anti-patterns flying around.
The vast majority of microservice systems I’ve seen aren’t really microservices at all. They’re separately deployable artifacts, sure. But they’re built in a way that, for developers, causes more pain than solves problems.
So let’s dive a little more into this. First, we’ll talk about what a microservice was intended to be. Then we’ll get into some of these anti-patterns.

What Does “Microservice” Mean?
As with many terms in the software industry, we have conflated “microservice” with plenty of things. For most people, it usually seems to mean “a deployment artifact.” However, it’s more than that. Members of ThoughtWorks developed the term in 2014. They were combating against the abuse of service-oriented architecture while still driving towards good software system design. As described here, microservices:
- Are autonomous, relying minimally on other services through lightweight communication mechanisms.
- Center around a business capability, in a similar vein to bounded contexts.
- Are heavily reliant on automated infrastructure to get into production.
- Require monitoring and good tooling to stitch together insights into what’s happening across services.
- Are designed for failure. A dependency going down should not bring down the entire service.
If we break these traits, then what we call microservices are not actually microservices.
How to Turn Your Microservice Into an Anti-Pattern
Let’s explore some common ways that teams take this original idea of microservices and twist it. I’ll share some of the top microservice anti-patterns that I have seen in the wild.
1. Ensure Your Services Are Around Technical Concerns
Centering your services around technical concerns is a surprisingly common microservice anti-pattern. I believe this mostly comes from combining two principles incorrectly: the single responsibility principle and clean architecture. Clean architecture says to use ports and adapters to isolate your business logic from things that need to use your business logic.
 This is all well and good, but it can easily mutate into something called layering, which is not all well and good. Layering was a key factor in the failure of service-oriented architecture. When you view everything in layers, your single responsibility sense kicks in and you say, “Well, I need to separate my persistence logic from my business rules logic.”
This is all well and good, but it can easily mutate into something called layering, which is not all well and good. Layering was a key factor in the failure of service-oriented architecture. When you view everything in layers, your single responsibility sense kicks in and you say, “Well, I need to separate my persistence logic from my business rules logic.”
So when someone says “microservices,” you decide you’ll follow what you have and make all these layers into different, separately deployed services. They may end up looking like this: security service, data services, orchestration service, business service. This goes directly against the idea that microservices center around a business capability. Healthy microservices would look more like this: shipping service, inventory service, ordering service.
It’s also common to slice out cross-cutting concerns, like auditing or email notifications, into a separate service. This will have the same pain points as layered services.
When you follow this anti-pattern, you ensure that your system will be:
- Very slow due to the latency in network calls across services.
- Susceptible to network failure since if one layer fails to get its data across the network, all downstream layers fail.
- Very hard for developers to add new features as they struggle to follow the code through all the layers.

You can avoid this through diligent design and understanding your customer’s needs. You need subject matter experts to help guide you through the different aspects of your business. Then, you can separate them out. It’s often helpful to start with a well-modularized monolith before splitting it into separate services.
2. Ensure Low Autonomy
Let’s say you’ve successfully avoided the first anti-pattern: your services have pristine names like inventory, purchasing, product, and customer support. However, you realize that your inventory service needs to talk to the product service in order to get some details on where in the warehouse a product belongs. And then you need to connect to the customer support service so that you can figure out which products customers really want so you can stock them appropriately.
Of course, whenever you run a request, you have to ping each individual service for information. Before you know it, you have a tangle of services all trying to talk to each other to do their jobs.
It can be even worse when two services try to talk back and forth like this:
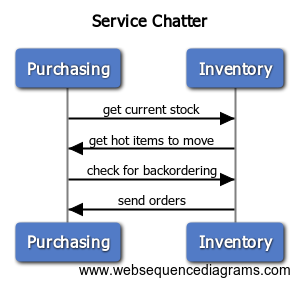
If your services follow this anti-pattern, they’re no longer microservices. That’s because microservices need to be (relatively) autonomous. They should not heavily depend on other services to do their work. By following this anti-pattern, you ensure that:
- Development is painful since you need to go back and forth to add or change functionality if within the same team.
- Each service team incurs a coordination cost to try to get both teams to align on when to make changes.
- Failure of one affects the others.
- Developers will get confused about who owns what data.
You can avoid this by doing a couple things. First, ensure you that you diligently figure out the boundaries such that the correct service owns the correct data. In the diagrammed case, inventory should own stock and storage locations but should not care about price or invoice numbers. Perhaps inventory may need to know when a customer places a new order, so it can fulfill the order. Or purchasing might need to know when an item is not in stock. In these cases, you can use event-driven architecture to ensure that when something happens to one service, the other services can follow up with their own actions.
3. Have a Tightly-Coupled Orchestration Service
In large organizations, it’s popular to slice development teams horizontally, similar to layering. They then try to bring it all back together with an orchestration service. Orchestration acts as a bandage over their self-inflicted wounds.
An orchestration service is not a microservice. Instead, it’s a vicious anti-pattern that is hard to combat. These services don’t revolve around a business capability. They’re also not autonomous. These types of services are not designed for failure. You cannot easily deploy them independently, as they are often useless until their underlying services are deployed.

The pain of orchestration services is similar to the above microservice anti-patterns. They:
- Slow everything down by adding network latency.
- Cannot respond faster than the slowest underlying service.
- Slow development across all services, as teams have to coordinate with orchestration to get their features out.
- Will often be blamed for any problems the underlying services have, and will not be equipped to understand these failures.
If you find yourself in this position, there are some things you can do. You can build your orchestrator to be as schema-agnostic as possible. Try not to transform anyone’s data unless absolutely necessary. If possible, push the composition of these services up to the customer-facing application.
4. Ensure That Your Service Fails When Another Service Fails
You may have avoided the pitfalls above and have only a few dependencies on other services when you make requests. But what happens when those underlying services fail? Teams may have low coupling to others, but if those dependencies fail, your service could grind to a halt. This is especially true of orchestration services. Taking our purchasing/inventory example, what happens if someone tries to place an order with purchasing, but inventory says the item is out of stock? Or even worse, what if inventory is not responding? Do you give up?
If you don’t design for failure, then your service is not a microservice. If you don’t design for failure, you might:
- Get blamed by your consumers for failures that you do not own.
- Lose customer trust with a higher-than-expected fail rate.
- Spend an inordinate amount of time spent on production support.
You can avoid this through various strategies. As stated above, trying to decouple the services through events works well. You can also add retries around your service calls, avoiding intermittent failures like network timeouts or dropped packets. If you’re sending commands, you can add queuing and offline processing. Then you can put the command “on pause” and try again when things are working. If you’re reading data, you can show an “empty value” on failure. You can also have a fallback cache of values to use if the service is currently non-responsive.
In Conclusion: Learn More
Microservices can be useful for handling large systems. However, you can see how easy it is to mess up and not have microservices at all, even though you think you do.
Follow these anti-patterns and you’re guaranteed to have a hard time. Be careful and diligent when separating your services. Learn as much as you can about your business processes and follow those seams when you design systems. Understand what microservices are meant to do and design accordingly, and you’ll save yourself lots of pain in the long run.

