
We mentioned a multitude of Kafka use cases in the prior blog post. As Scalyr introduced the Event Data Cloud, it’s essential for us to build a reliable and scalable Kafka connector to stream Kafka events to our platform for monitoring and future analysis. I have written knowledgebase articles on how to set up Kafka connector to ingestion application logs, so I want to focus more on the benefits the connector brings to the users and how it simplifies sending Kafka messages to Scalyr in this blog post.
Easy to Configure
Before the Scalyr Kafka connector was introduced, Kafka users might have chosen to implement their own Kafka consumer to send Kafka log messages to Scalyr. There’s a multitude of open-source Kafka client libraries for development, so it’s not a difficult job to build an application that reads Kafka messages and makes RESTful API call (i.e addEvents) for ingestion.
However, selecting the right configurations could be challenging and there are a number of parameters that need to be taken into consideration.
- What’s the optimal value of “max_poll_record” to maximize performance?
- What’s my offset commit strategy?
- Do I need to assign “group_id” for every consumer?
- Do I need to configure timeouts interval?
Those parameters could be critical based on the use cases. For instance, committing the offset before catching exceptions could result in data loss, and configuring higher session timeout intervals than the request timeout intervals may shutdown the consumer prematurely.
Scalyr Kafka connector simplifies configurations with automatic offset management, and the partition offsets are stored in an internal Kafka topic. The framework is designed for integrating Kafka with external systems, so it’s straightforward to deploy the connector with your existing Kafka clusters and manage it at scale. Users only need to specify the converter class and the number of consumers to process Kafka topic’s messages.
Easy to Scale
Scaling in Kafka is typically done by adding extra consumer threads. The Scalyr Kafka connector also adopts the same concept with the “tasks.max” parameters in the connector’s configuration file. In addition to spinning up more consumer threads, users can add more workers to a Kafka Connect cluster to achieve horizontal scalability.
In regards to data ingestion, Scalyr Kafka connector utilizes the addEvents API directly because we can easily control the timing of the messages to be delivered to Scalyr, and the Kafka concept matches well with our addEvent API’s specs. For example, the Kafka topic’s partitions are “immutable” so that a producer can just append messages to a partition itself and increase its offsets. Therefore, we just map the topic’s partition and partition offset with API’s sequence id and sequence number. This mapping structure enables assigning a unique sequence number for each message and using it for deduplication.
Basically, we built the Kafka connector to handle addEvents API usage internally and optimize its performance, so scaling becomes a measurable and manageable task that users don’t need to worry about.
Easy for Troubleshooting and Error Handling
Kafka Connect framework provides REST APIs for managing, monitoring, and debugging connector. All you need is a couple of API calls to make sure that both the connector and task are running to ensure that the data will be forwarded to Scalyr.
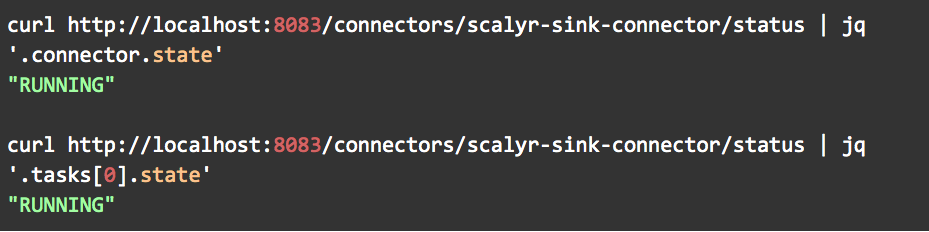
REST API
Here is another example of viewing the stack trace of the connector using the REST API. In this case, a message received by the connector doesn’t match with the converter/serialization specified in the configuration file.
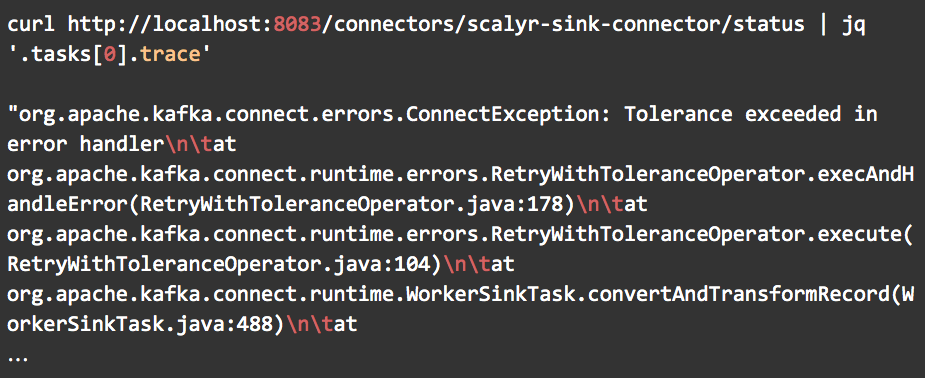
This is a common issue as a message could be accidentally pushed to the topic without knowing the message’s format constraints on the topic. There are different approaches to handle this situation. By default, the connector crashes immediately, but you could choose to ignore the bad messages completely without notification. My favorite option is forwarding the bad messages to another topic, so we can keep records of the incompatible messages.
Here is an example config to send the bad messages to another Kafka topic “error-log”.
"errors.tolerance":"all",
"errors.deadletterqueue.topic.name":"error-log",
"errors.deadletterqueue.topic.replication.factor":1,
"errors.deadletterqueue.context.headers.enable":true,
"errors.retry.delay.max.ms": 60000,
"errors.retry.timeout": 300000,You don’t need to implement your own validation logic and/or write a producer to send the data. Adding the above config parameters to the configuration file should just do the job, so error handling is really easy since the feature is already part of the stack. You can refer to this confluent blog post for more information on error handling and dead letter queue.
If Kafka is part of your ingestion pipeline, you should check out our Kafka connector. We’d love to hear your feedback!

