
As you see technologies getting advanced every now and then, it’s worth thinking about where our industry is headed. There are many exciting and challenging developments ahead: blockchain scalability, functions as a service, databases as a service—the list goes on.
We’re also moving more and more into an increasingly complex, distributed world. This means distributed tracing will become especially important. And distributed tracing is something that will make it easy for you to deal with complex systems. In today’s post, we explain why that’s so.
We start with a quick definition, explaining what distributed tracing is. We don’t stop at the “what,” though: we take a step further into the “why”, covering a little bit of the motivations behind its use, particularly in what it relates to microservices architectures.
After that, we talk a little bit about how distributed tracing works. We then follow that with the main challenges with complex systems and explain how distributed tracing can help us beat them. Finally, we wrap up with a summary of all we’ve covered, along with some final recommendations. Are you ready? Let’s get to it, then.

A Quick Definition
Before I explain why distributed tracing is so important, let me explain what it is.
Put shortly, distributed tracing is a new form of tracing, more suited to microservice architectures. You can use it to find problems and improve performance by profiling and monitoring applications built using a microservices architecture.
Distributed tracing tracks a single request through all of its journey, from its source to its destination, unlike traditional forms of tracing which just follow a request through a single application domain.

In other words, we can say that distributed tracing is the stitching of multiple requests across multiple systems. The stitching is often done by one or more correlation IDs, and the tracing is often a set of recorded, structured log events across all the systems, stored in a central place.
Distributed Tracing: How Does It Work?
It’d be out of scope for this post to give a detailed overview of distributed tracing workings, but that doesn’t mean we can’t cover it briefly.
The whole process starts with the event being traced and the single request associated with it. As we follow this request, many entities within our distributed system perform operations on it. Those operations are recorded using traces, that are generated by the single original request.

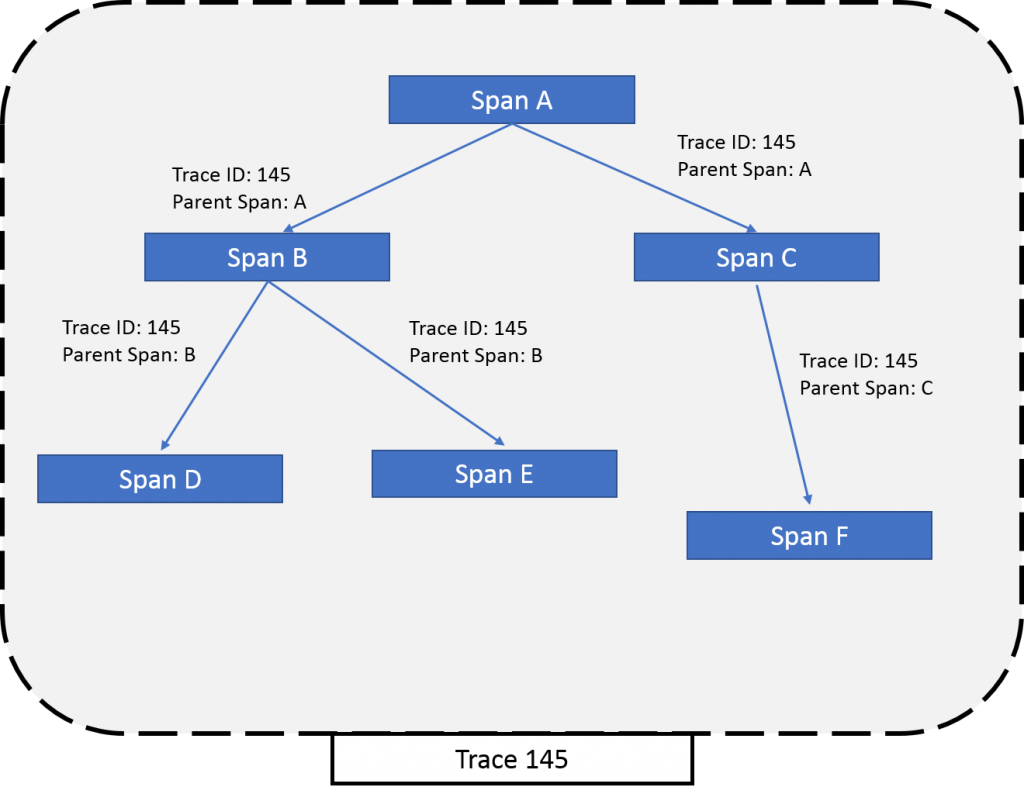
Every trace has a unique ID and goes through a segment we call span. Each span indicates a unique activity performed on the request by a host system, and it also has a unique ID (a.k.a Span ID), besides a name and a timestamp, and optional metadata. Span is the basic component of the trace. Whenever there’s a request flowing through the system, every activity associated with it is recorded in the span. When one activity is over, the span(a.k.a. parent span) refers to the next span(a.k.a. child span) for the next activity. All of these spans put together in the right order forms the trace.
When there are multiple spans, it is important for every span to know which parent it belongs to. So, every parent span passes its span ID and trace ID to its child. This information is known as SpanContext. SpanContext helps in maintaining the relationship between spans to form a complete trace.
Challenges and How Distributed Tracing Can Help
Up until now, we’ve tacked the three big questions of distributed tracing: What is it? Why use it? How does it work? But we haven’t explained why it is so critical.
Put shortly, distributed tracing is the tool we need to help us beat the most significant challenges we’ll be facing as technologies advance and get more complex.
From Modularized Monoliths to Microservices
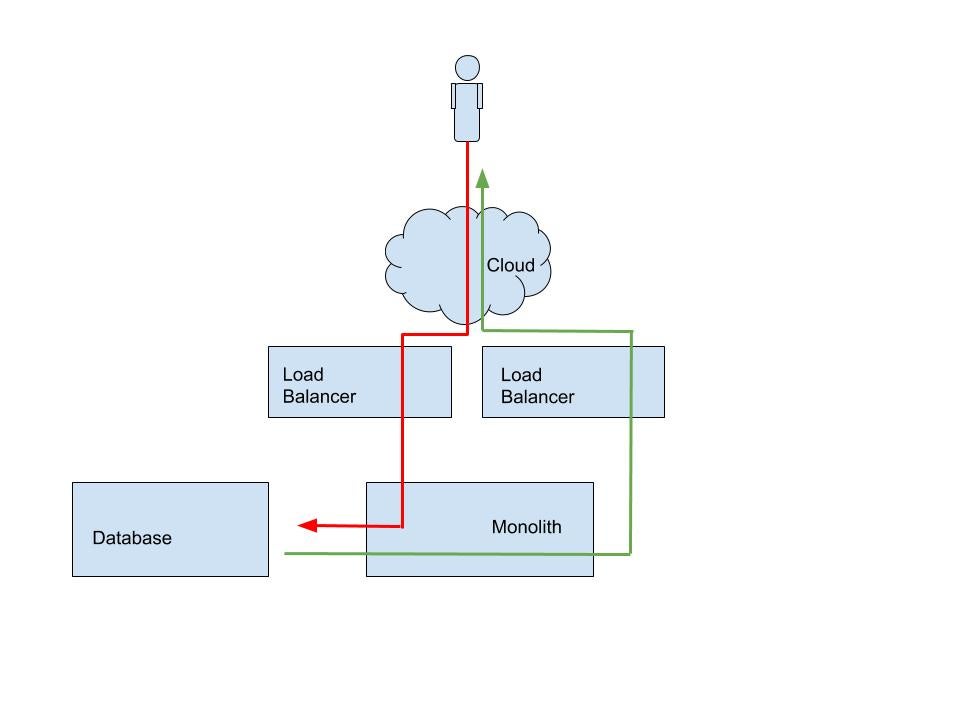
The first challenge is the fact that software systems are much more distributed than they used to be. In order to deepen our capabilities within organizations, we’ve had to subdivide software features not just by modules, but by entire deployment pipelines.

We’ve gone all-in on microservices, pushing systems that once communicated in-process to now communicate across networks. This brings all the fallacies of distributed computing along for the ride. It becomes easy for individual teams to build and manage their services but they wouldn’t know what’s happening outside their scope. There might also be cases where microservices when tested individually work absolutely fine, but when all the services are put together and an end-to-end request is made, you see problems. Distributed tracing makes identification of such bottlenecks easy which would result in an early fix.
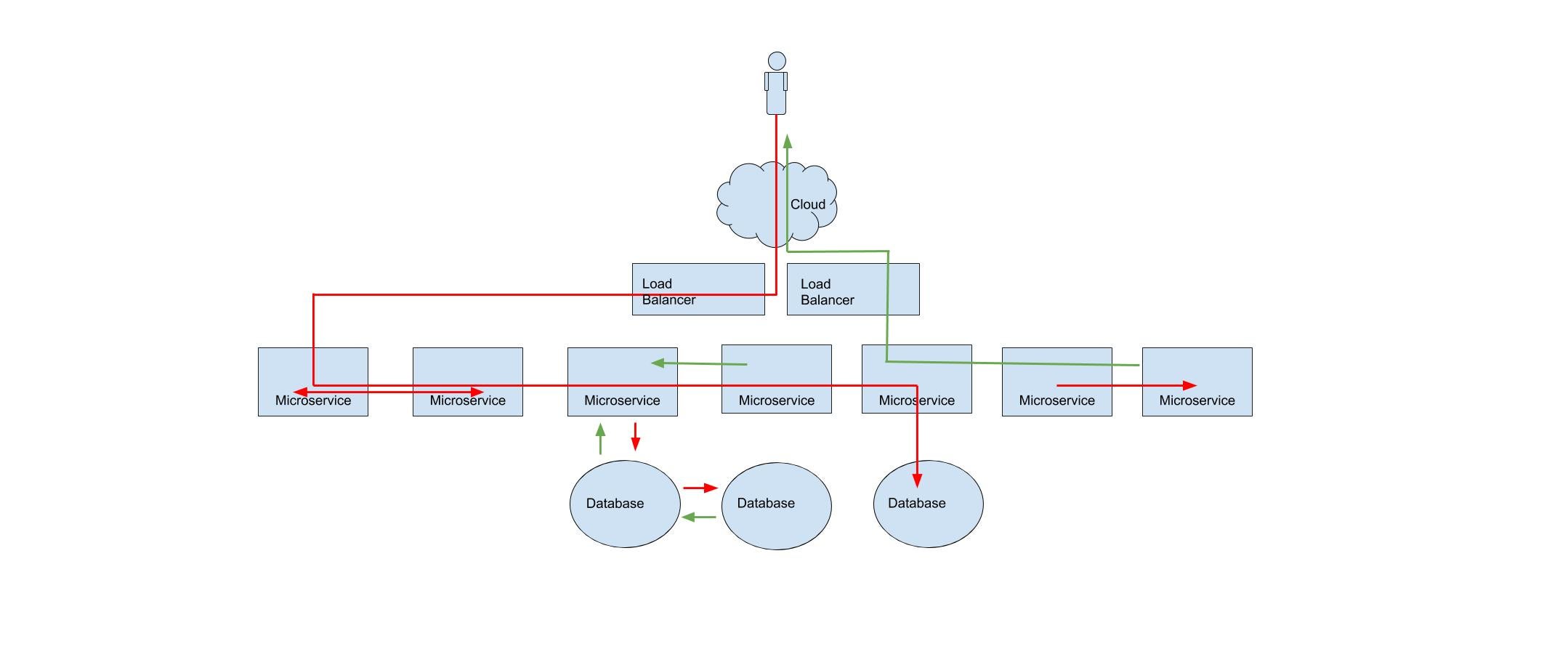
Network issues are often intermittent and exist outside any one software team. Which means that now we need something that can work across multiple teams.
The Climb of Complexity
The second challenge is an increase in complexity. In many organizations, it’s reached a tipping point where we can’t simply apply the same tools we’ve used for the past 20 years. We’re automating more and more parts of our businesses. And, using tools like machine learning, we’re deepening the complexity of systems we’ve already automated.
For many organizations, software complexity has gone so far that it’s overwhelmed the capabilities of human minds. Even for one value stream, the number of people and systems we need to touch is too high for us to anticipate every edge case and every risk. Add to that the fallacies of distributed computing. We must be ready to deal with systems with a lot of unknown risks. And distributed tracing helps you get clear visibility of such systems.

Too Many Problems to Anticipate
We must face the fact that increased distribution has built many risks that exist outside any one software team. And, because complexity has overwhelmed our minds, the chance of unknown unknowns has gone up.
Let’s back up for a second and talk about knowns and unknowns. For risk, these come in four different categories:
- Known knowns: These are things we’re aware of and understand. For example, I know that if we don’t validate that a product code has five characters or fewer, the order submission process will throw a 500 error. We can easily test-drive these things out.
- Known unknowns: Things we’re aware of but don’t understand. Example: We keep running out of database connections but aren’t sure which processes are hogging them all. We can prevent many of these with good architectural design and quality gates.
- Unknown knowns: Things we’re not aware of but understand. Example: We know that unvalidated data will corrupt our Order Submission service. However, we don’t know which endpoints have no validation. Again, good architectural design and quality gates prevent these sorts of things by making quality part of the design of each feature.
- Unknown unknowns: Things we’re not aware of and don’t understand. Example: Unbeknownst to us, at midnight the router changes policies and causes a race condition in the Order Submission service, which in turn triggers orders to be fulfilled twice in the warehouse.
Unknown unknowns are problems that we could not have possibly predicted. Any attempt to prevent these types of issues ahead of time is a fool’s errand. We’d spend exorbitant costs trying to create crystal balls and would wind up not making any changes at all. After all, no changes mean no risk.
Medicine That Works After Software Gets Sick
Since we can’t predict these unknown unknowns, we need to apply tools that fix issues quickly after they happen.
Let me put it another way: We can heed all the nutritional and physical health advice in the world, but eventually, we all get sick at some point. The same is true for software systems: They all inevitably get sick. When a person is sick, we don’t say, “Well, just exercise some more.” That advice may be helpful to prevent future issues, but it doesn’t help the person at the moment. Instead, the doctor will say, “Get some rest. Take these antibiotics and call me if your symptoms persist.”
With sick software we can’t say, “Let’s create automated tests for every potential disease that might inflict our system.” Instead, we need ways to deal with problems after they’ve happened. It’s great to take measures to prevent problems but you can never be 100% sure that no problems will arise.

This is why distributed tracing will be so important in the future. It doesn’t attempt to predict the future. It simply tells a story of what’s already happened in our systems. So quick identification of problems helps in quick resolution of problems. Distributed tracing helps you with this and also tells you what caused the problem which releases you from the issue hunting adventure. Tracing also is built to tell that story across the entire network. You can even involve your routers, firewalls, and proxies in a distributed trace.
Stitching a Story
As I said, distributed tracing tells a story of what’s happening in a software request. It’s simply recording what it tracks. As humans, we’re good at following stories. This makes distributed tracing a great fit for us to quickly deal with unpredictable problems.
However, this benefit doesn’t come for free. A key to telling a great story is to include the right level of detail. This means we need to design observability into our features and user stories up front. We have to think about ourselves as first-class support personas.
There are specifications that make this easier to do, but we still have to think about this as we design our systems. But, at least we don’t have to predict what problems might appear. Stitching stories can be difficult when you have to do everything from scratch. To make it simple, you can use monitoring frameworks.
OpenTracing and OpenCensus
OpenTracing and OpenCensus are two distributed tracing frameworks that help you integrate tracing within your systems easily. Both of these have various APIs and libraries and provide multi-language support and have become an informal but standard approach for distributed tracing. OpenTracing is a vendor-agnostic tool that provides support for almost all popular languages such as Python, Java, etc. OpenCensus is based on Google’s Census which provides end-to-end functions from collecting traces to sending it to the backend in a common context format.
Distributed Tracing: Your Storybook
Let’s review why distributed tracing will be so important in the coming years.
We know that software systems are climbing higher in complexity. We also know that we’re slicing these systems into smaller and smaller deployable pieces, even down to the function. These systems are now too complex for our human minds to anticipate all the problems that might arise from their use. We need to put tooling in place that can quickly detect and fix these risks we can’t anticipate.

Distributed tracing is one of the best ways to track down these unexpected problems. It doesn’t assume what problems will crop up in the system. Instead, tracing tells a story across a network, and we’re good at following stories. If you’re responsible for any of these systems, distributed tracing is an absolute must.
What should your next step be? In short, do your best to stay tuned to what’s happening in the industry.
A sure way to do that is to follow the very site you’re reading right now, the Scalyr blog. We are always publishing useful articles, bound to help you not only with tracing but with your overall logging and monitoring strategy. While you’re at it, you can take a look at Scalyr’s offering, a log aggregator service that can certainly help you with distributed tracing. Give Scalyr a try today.

