
Nothing in this world is 100% foolproof. Believe it or not, you can’t build something that never fails! But even though you know this, you might still find yourself striving for perfection. Why? After all, full reliability is usually out of reach. Even if you want your business to have the highest reliability. So, don’t you think delivering value is more important?
Do you know the biggest mistake some firms make? Focusing on extreme reliability. So, how about knowing how to recover from failure? We know that site reliability engineering (SRE) is all about balancing unavailability risks. Along with that, you need to keep efficiency and innovation as the goals. Not to mention, flawless user experience is the key here.
Thus, there should be a clear metric to determine the unreliability of a service—meaning how much you can compromise reliability within one quarter. That’s where error budgets come in.
On that note, this article will discuss error budgets in detail. First, we’ll check out what an error budget is. Then, we’ll take a look at why we need an error budget and how to make it work. After that, we’ll also understand why we shouldn’t aim for 100% reliability.
So, let’s dive right in!

What Is an Error Budget?
An uptime of 100% is a promise no firm can ever keep! Therefore, you need to set a length of time that you can allow your systems to fail. We call this time the “error budget.” In other words, an error budget is the amount of time you can afford for a system to be down without violating a service-level agreement (SLA)—meaning no drastic contractual outcomes! For example, instead of promising a 100% uptime, you can mention 99%. That way, you can move up to 99.5% and finally 99.99%. Take a look at this table to see how percentage converts to time.
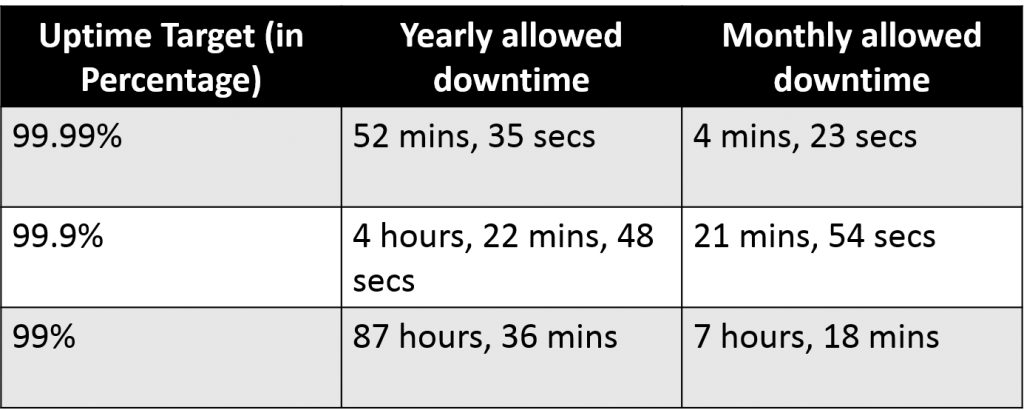
Let’s say you have a file storage service where your users can upload, store, and download files. If you have 100% uptime mentioned in the SLA, that’s the promise you’re making to your users. In that case, the objective of your organization is to maintain 100% uptime. This objective is known as a service-level objective(SLO). It’s important to track the uptime of your service to make sure it is compliant to the SLA. This is done using a service-level indicator(SLI). The SLI measures the actual uptime to compare it with the SLO. The actual uptime should always be greater than or equal to the promised uptime (that roughly means SLI >= SLO). Failing to achieve this could result in loss.
You must have heard of corporate leaders losing millions in the blink of an eye. For instance, Facebook, Apple, and Delta have been victims of extreme loss. How does this happen? After all, these giants never compromise on reliability! At least they don’t intend to. It’s because they declared 100% uptime in their SLAs. On that note, let’s discuss why we need an error budget.
Why Do We Need an Error Budget?
To most IT workers, the error budget might not seem vital at first glance. Having an error budget enables you to take calculated risks. This means that these risks are within acceptable limits.
An error budget also bridges the gap between developers and operators. Developers try to be as agile and innovative as possible. But the operators have to take care of security and stability. Often, these two teams can struggle to be on the same page. When the downtime is low, the operators won’t stop the developers from making changes.
Perhaps if we lived in a perfect world, there wouldn’t be a compromise between innovation and uptime. However, in the real world, it’s important to strike a balance between the two. An error budget does just that!

An error budget is also a lifesaver when it comes to dealing with outages. For instance, suppose you’re the owner of a data center facility. One day, you face a network outage. What would you do in such a scenario? Of course, you must estimate for incidents like this beforehand and add them to the error budget. The reason being, suppose you don’t add this event in the error budget and you lose an hour of service because of a network outage. In that case, you have to pay a penalty to your customer if you’ve agreed for a 100% uptime in the SLA.
Sometimes a team might have really high-reliability goals. In that case, an error budget highlights costs in terms of slow innovation and inflexibility. If you feel troubled to launch new features, you might need to loosen up the service-level objectives. That is, increase the error budget to ensure continuous innovation.
How to Make an Error Budget Work
Sometimes things happen that are external to deployment—for instance, internet issues or anything that’s beyond your control for that matter. In that case, it’s vital to have some room in your error budget. On that note, let’s discuss some best practices that’ll keep your error budget in the positive range.
Don’t Be Hasty While Pushing New Codes
The best way to make an error budget work is to push changes slowly. This way, you have better control over the error budget. Suppose you’re going to deploy a large piece of code. But for some unforeseen reason, an issue occurs. As a result, you have to perform a rollback of the entire code. The ideal thing to do in this case is to deploy small code changes. If some issue happens, before letting it consume your entire error budget, you can roll back. Here, automation is the holy grail. Use continuous integration. After all, every fraction of a second counts when you have to roll back!
Have a Failback System for Everything
Always make sure that your application can support issues that arise due to dependencies.
Let’s say that your system offers different microservices. If one goes down, the client should have the option of taking data from the local cache. A default response would also be viable in this case. Not only that, ensure that you have a multiserver architecture. While pushing in new code changes, push the code in one server. If everything goes well, pass the code to the other servers in a sequence. You can also opt for serverless deployment. Thus, your customer will face zero downtime during deployment.

Also, monitor the logs of your application constantly to ensure that whenever something goes wrong, you get an alert immediately. You can take a look at Scalyr’s solution for log management, alerts, monitoring, and visualization of metrics. Monitoring servers can also be helpful in collecting uptime related details. After collecting them, you can extract various metrics that tell you about the uptime. You can then use these metrics to calculate SLI.
Be Prepared for Failures
Never be scared of failures. Always remember that the key to impressing your users lies in how you manage failures. For instance, let’s talk about the example we discussed in the previous section. You can’t afford to bring the servers down if there’s a failure. If you have a multiserver architecture and some issues arise during deployment, the other servers stay active. This doesn’t affect the browsing session of the client. But if you don’t have a backup solution in case of a deployment issue, you’re at risk. Hence, when you have an error budget, consider all the important metrics.
Now, some might say that every change has an impact on the system. But that doesn’t mean you stop making changes in the name of avoiding risks. It’s better to adopt other ways to maintain stability. However, it’s not necessary that the error budget you’re making is always accurate. On that note, let’s discuss why you should not aim for a 100% reliable error budget.
Why Not to Aim for a 100% Reliable Error Budget
When you’re creating an error budget for the first time, it’s easy to go overboard. In fact, this applies to your general budget as well. For example, suppose you’re setting a budget for household supplies. So, in the beginning, you might want to save up as much as possible! In this case, what’s the most common mistake you’ll make? Of course, setting an unrealistic target.

When your budget goals are off the charts, you’re more likely to derail. It happens when you fall even a little off track. Ultimately, you end up breaking your budget. Now, there’s no guarantee that you won’t splurge a bit. So, what do you do in this case? Leave some wiggle room for unexpected scenarios to prevent yourself from falling too far.
Similarly, in SRE, extreme reliability can do more bad than good. It can reduce the features a company can offer to customers. Instead of striving to only maximize uptime, focus on balancing unavailability risks. Also, even if you assure 99.99% reliability, a lot depends on the internet connection and the device of the end user. The user experience won’t be optimum if their internet is slow. Thus, even if you promise maximum reliability, some factors will always be beyond your control. The conclusion: never aim for an error budget that’s 100% reliable.
Provide More Value With a Flexible Error Budget
Now that we’ve established the “not aiming for 100% reliability” rule, let’s simplify something. If you have more scope in the error budget, you can take some risks. But if you’ve drained the error budget, you can take risks only with lots of limitations.
So, if you worry too much about reliability, innovation is bound to come to a halt. Sure, you’d like to avoid risks at first. However, let’s be real for a moment here. Do you really think anyone cares about reliability if a system fails to provide any value? All in all, the system should solve users’ problems.
For instance, if you’ve been rock solid on the reliability of 99.99%, you may notice that it’s too hard to develop new features. So, if you downgrade a bit to 99.9%, or even a bit less for that matter, you can grab some more scopes and move faster. Now, this isn’t a strict rule you must follow. Consider this as a guideline. This way, you won’t have to fret over striking a balance!

