
Publishers are producing massive amounts of data daily. We as consumers are always looking for pieces that match our needs. Apache Kafka is a service in the middle of this ecosystem, helping us access the data relevant to us in a manner that doesn’t clog the networks. This Kafka tutorial will take you through an introduction to the service.
In this post, you’ll find out about the terms and concepts that engineers use when incorporating Kafka into their application workflows. You’ll also get a brief introduction to the architecture of Kafka. This information will make it easy to see where and how to use Kafka in your own projects. As a cherry on top, we’ll cover a few use case explanations to further clarify how to use Kafka in real-life systems. (If you’re unfamiliar with Kafka, you can see the logo here.)
Once you install and set up Kafka, you’ll be ready to implement your own scenarios. But before we jump into the installation, let’s do a brief walkthrough of the history of Kafka. This little trip should give you an idea of how much you need Kafka and how many companies agree on its usefulness.
A Brief History of Kafka
Kafka was first a service used solely by LinkedIn to handle their data transportation and access internally. In 2011, LinkedIn donated it to the public as an open-source project under the Apache license. Since then, data streaming services such as Netflix, Apple, and Citi have used it.
Why have some of the biggest companies in the world adopted Kafka? It makes scaling data access services and integration with third-party applications very simple compared to building new systems from scratch. The distributed data streaming capabilities of Kafka mean that storage component failure is resolved automatically. We’ll discuss the “how” part later in the tutorial.

What Kafka Is
The official definition of Kafka by the Apache Foundation is that it’s a distributed streaming platform. Parsing that description of the platform leads to two important discoveries about Kafka.
- It’s distributed by design. This means that you can store and process data while it’s in different locations.
- As a streaming service, it processes data between source and consumer. Also, it reacts in a real-time manner to queries from both ends.
Kafka’s Features
Telling you that Kafka is among the leading real-time data streaming platforms makes sense only when you know what you can do with it. These features are why companies across entertainment, communication, finance, and more sectors are currently using it.
- Kafka permits free data handling and distribution.
- Low data latency is attainable with Kafka.
- It simplifies horizontal scaling.
- Kafka can be a data storage, streaming, and maintenance platform all at once.
- Kafka improves fault tolerance when you’re processing data in real-time.
These are just a few of the very convincing factors that have resulted in Kafka being one of the most widely used data streaming and processing platforms in the world.
In the next section, we’ll look into the architecture of Kafka and discuss just how it accomplishes these feats.
Kafka Architecture in Detail
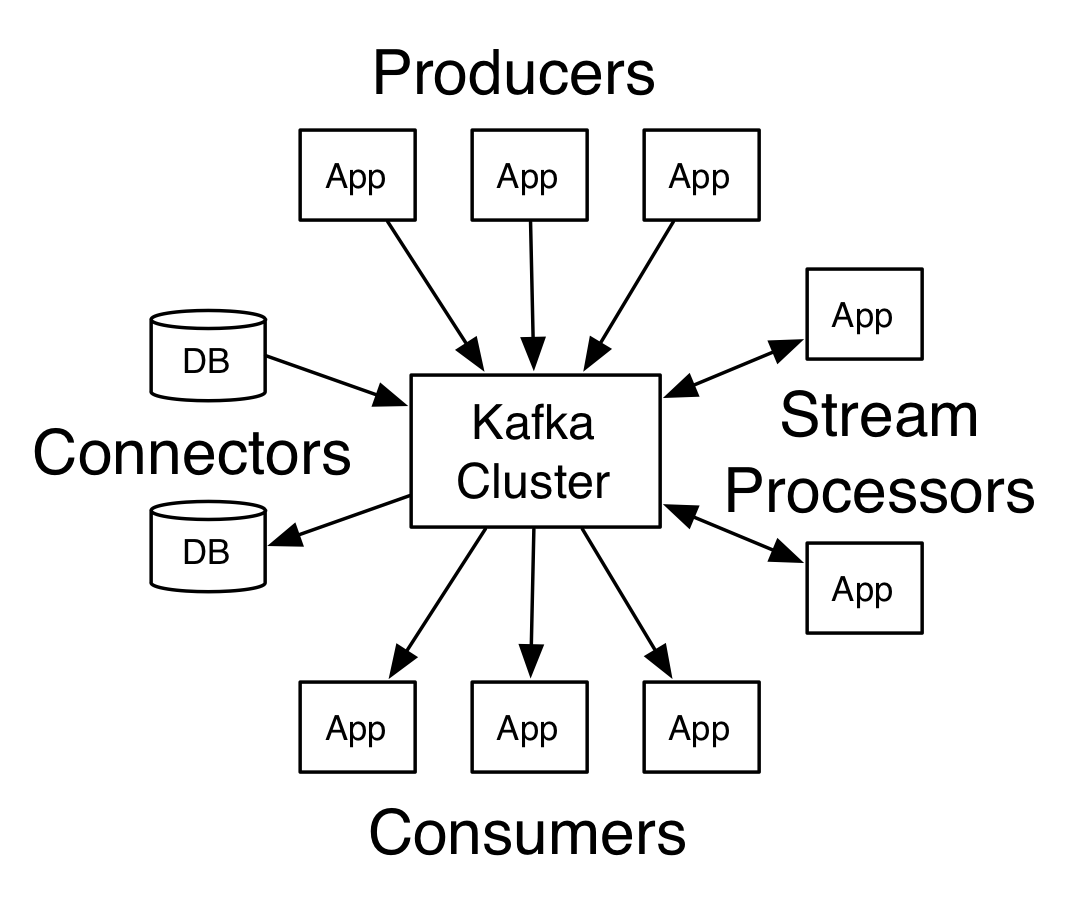
To understand Kafka to the levels that’ll make you comfortable using it to build your applications, you should get familiar with the architecture and the terms that the engineers working with it use. Sticking with the producer/consumer data relationship example you saw in the first paragraph of this tutorial, the architecture (skeleton) of Kafka looks like this diagram.
What’s important to know about Kafka’s architecture?
- The producer can be any source of data that pushes it into Kafka clusters.
- These clusters often contain brokers that store the data in redundant sets.
- Kafka may store a topic over a network of three to five data centers in different locations. Already you should start to see how that brings about high uptime rates.
- Think of brokers as databases storing topics, with partitions as tables of the records. Focusing your attention on the partition allows you to know more about how Kafka actually stores, organizes, and presents the data once a consumer sends a fetch request.
Now, let’s look at the partitions part of Kafka in more detail.
Kafka Partitions
By design, a partition is a member of a topic. Topics have names based on common attributes of the data being stored. This can be messages, videos, or any string that identifies one from the rest.
Once the topic has a name, that name can’t be changed, and this also applies to the partitions inside each topic. Essentially, all the data fed into the topics and their partitions remain unchanged. It’s possible to copy the data to create instances of itself, but it isn’t editable.
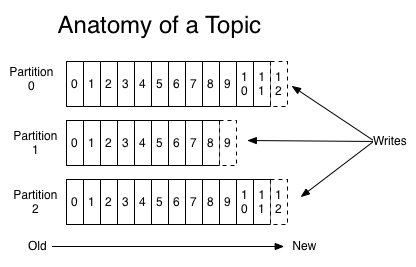
When data goes into a partition, the timestamp is the default sorting criterion from old to new. The new data added after that has an incriminating offset as a position identifier within the partition, starting from 0. This value is non-negative and always increases by a factor of 1, even after the user or the system deletes a record based on a retention policy.
By default, the data in partitions persists for a week before it expires. Even when that happens, the system won’t allocate any other record to the offset in the future. This diagram can help you understand how partitions work.
How can you send data to the right partition for the right consumers to access it? This skill often requires knowing the key specifying the partition from within all the others in a cluster’s topic.
Kafka runs with the help of Zookeeper, a service that manages configurations, naming policies, and grouping. Zookeeper provides a stable distributed architecture for applications. It’s also an Apache-grown project. You’ll have to install it as a prerequisite when we get into the setting up part of this Kafka tutorial.
The Kafka Consumer
On the consumer end, each group accesses data from the partition on demand. The data isn’t pushed to the consumer. Instead, the consumer pulls it through a query.
The consumer can be a database of specific data types. It can even be a metrics dashboard using the data for real-time log management and presentation, as is the case with Scalyr.
Kafka’s design makes it possible to extend the performance and structure into custom applications through various application programming interfaces. Let’s explore those next.
Kafka APIs Explained
Kafka allows interaction with custom applications, allowing you to extend its functionality. As you can see from this diagram, Kafka can handle a lot at once.

You can access five core APIs when using Kafka. This list arranges them so their implementation starts from the publisher to the consumer.
- Applications on the publisher’s side use the Producer API. It controls who can gain write permission to topics and partitions in a Kafka cluster.
- The Connector API allows you to create and maintain live transactions between clusters on both the publisher side and the consumer side.
- The Admin API grants controlling rights. It lets you inspect each component on the architecture and make administrative changes for upkeep.
- The Streams API is the processing calls manager that arranges or queries data from publishers into usable output topics for the consumer.
- The Consumer API gives access to the topics when a consumer passes a request.
All of this information is helpful, but what does Kafka’s usage look like in real-life scenarios?
Real-World Kafka Use Cases
By now you have a high-level understanding of the way Kafka’s creators built it. Let’s look at how its structure favors real-life applications. Most if not all of the use cases of Kafka are strong on using the guarantees that come with its implementation. These guarantees include a very impressive throughput, low latency, and fault tolerance. These characteristics make it useful in a world where if your app is brittle, users will flake off.
Kafka Messaging Implementation
The most obvious implementation of Kafka is as the broker for a live communication channel. One example is the Twitter implementation scenario, where topics and their partition need to be distributed for access to millions of consumers all at once. The distributed architecture makes it possible for such a use case to attain an almost perfect uptime record. This is because geolocation scaling of its servers means less traffic on any single data center. Twitter content and messaging services are lightning-fast. That’s thanks to the high throughput inherited from Kafka as its broker and cluster handler.

Log Management With Kafka
Data-sensitive systems can use Kafka as the log data handler. Not only will this make their resulting system quicker, but they can use the core promises of Kafka to themselves be low resource consuming while giving clean real-time data on system states. As is the case for Scalyr, connecting an output topic of choice into custom visualization tools can result in a monitoring and troubleshooting application for infrastructure services, such as a Kubernetes-based setup. The same concept works when building website metrics dashboards. In that case, it’s possible to implement even a broadly distributed system with Kafka. The data goes into a central application to give an overview and decision making power at just a glance.
Content Streaming Services With Kafka
Netflix is a notable usage case for Apache Kafka. The video content that many of us enjoy is a good example. Also, previous consumption logs are a perfect implementation example of the Kafka architecture and its guarantees. Coupling these predictable characteristics of Kafka with the Streams API to process the usage logs of each user, and recommending topics that are likely to be of interest, makes for an unparalleled entertainment experience. Accessing your viewing history on Netflix is another instance where you’re exposed to the logs topic. It updates each time an event (such as watching a new movie) takes place. Sure, Kafka is useful and impressive. But what makes it safe?
Kafka Security Features
Kafka never negotiates security, no matter what the use case. Payment platforms such as PayPal and Citi run their data through Kafka implementations. Data encryption between publishers and clusters, as well as clusters and consumers, reduces threat levels significantly. However, this level of security isn’t a default in Kafka. You have to set how secure your implementation is based on your policies.

Apache Kafka Installation Tutorial
At the time of writing, the latest stable version of Apache Kafka is 2.5.0. The previous version had been stable and in use for close to a decade. As previously mentioned, you can’t run Kafka without Zookeeper. This means you’ll have to download both installations from the official Kafka documentation platform. Here’s something to consider before running your installations and the accompanying scripts: What platform will you be working from? This Kafka tutorial will create a single Zookeeper instance. And that will allow you to play around with a few topics in a single cluster.
Running Zookeeper and Kafka
The first file you’ll have to navigate to and run is Zookeeper. Make sure the file extensions go with your operating system. Look for .sh for Linux and .bat for Windows. The script below should make light work of this part.
> bin/zookeeper-server-start.sh config/zookeeper.properties
This tutorial assumes you already use the machine for development purposes. As such, it should have all the required frameworks and Java Development Kit to make the environment suitable for the rest of the process.
With this out of the way, you will have successfully started an instance of Zookeeper. Now you can start Kafka.
> bin/kafka-server-start.sh config/server.properties
After this command runs successfully, you will have automatically created a cluster through the auto-config characteristic inherited from Zookeeper.
You can create topics by either of two methods. The first one is through creating automatic topics when one is created that didn’t already exist. The second would be explicitly stating the name of your required topics on creation through a command in the command-line interface.
> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
This topic has a replication factor value of 1. What does that mean? While you create a single topic, the system duplicates it for redundancy and distribution goals.
To create some messages to place inside the new topic, insert this code.
> bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test Testing Another test
This command starts a default producer command-line interface that allows you to input messages into the topic you’ve created.
Leaving it open, run the next command to create the consumer output window.
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning Testing Another test
At this point in our Kafka tutorial, you have a distributed messaging pipeline. It takes input from the producer interface and places each new line as an entry into the topic you declared. It also immediately shows its contents in the consumer interface. Nice job!
Now that you’ve spent a bit of time working with Kafka, let’s talk about ways you might use it.
Building Real-World Applications With Kafka
More complex implementations of Kafka are possible, no matter what programming language and framework creates the applications. Why? Because your application will need to attach itself to the Kafka service through the application programming interface.
As far as its makeup, Kafka is Scala and Java under the hood. The team developing the Kafka project intends it to be perfect for data critical situations. Cases that have above-average volumes of messaging passing as log data perform very well with the Kafka Stream API. To start using it on a sample application for experimentation purposes, Apache provides documentation with source code for quick results.
An application programming interface in itself, Kafka Streams is the client-side library. It hinges on how easy it is to create front-end applications with Scala and Java. The data manipulation part happens on the server-side layer. This is where microservices run on Kafka’s principles in the way you’ve seen throughout this tutorial.
You won’t have to write any code to create your first application with Kafka Streams. This detailed and documented Kafka Streams tutorial should take you through the entire process.
Kafka Tutorial Conclusion
After you’ve had a chance to experiment with Kafka through this tutorial, you’ll realize that it essentially boils down an otherwise very complex process. We seldom notice it, but most of the applications we use daily run on the model and concepts around Kafka.
With the information in this post, you should be able to build a sample application. It should be clear how to build on it to experience the benefits of using Kafka application programming interfaces in your projects, even when you’re not about to make something with Kafka. And being familiar with some companies that are already using it should give you the knowledge to pick third-party services providers that meet your requirements. Best of luck to you as you explore Kafka.


{kind=link}
{kind=link}
{kind=link}
{kind=link}