Executive Summary
- Large Language Models can perform static malware analysis, but individual tool runs produce unreliable results contaminated by decompiler artifacts, dead code, and hallucinated capabilities.
- We built a multi-agent architecture for reversing macOS malware that treats each reverse engineering tool (radare2, Ghidra, Binary Ninja, IDA Pro) as an independent, skeptical analyst in a serial pipeline, where each agent must verify or reject the claims of the previous one.
- We examine a concrete design decision: why we chose deterministic bridge scripts over the Model Context Protocol (MCP) for tool integration, and how this affects accuracy, latency, and token cost in production.
- We document the model routing strategy and some real-world challenges encountered during development.
Why Single-Tool LLM Analysis Fails
Anyone who has taken decompiler output, a string dump or raw disassembly from a binary, pasted it into an LLM, and asked “what does this do?” will recognise the failure mode. The model produces a confident, well-structured report that looks plausible until a human reviewer checks the virtual addresses and finds half the cited functions are wrong, several “capabilities” are actually dead code from the compiler’s standard library, and the claimed C2 endpoint has an extra character because the string extraction tool mangled a forward slash.
These failures are not hallucinations in the usual sense. The model is doing what it was asked to do, reasoning over the data it sees. The problem is that the data is noisy. Each reverse engineering tool brings its own parsing quirks. Radare2 string blobs can mangle delimiters; Ghidra’s decompiler might misclassify compiler stubs as application logic; IDA’s Hex‑Rays pseudocode can elide important register‑level details. If an LLM treats these outputs as ground truth, artifacts can make it into the final report that lead to erroneous “confirmed” capabilities.
Our experience has long taught us the value of using multiple tools to enrich our understanding of malware design and capabilities. Therefore, we set out not to try to build better prompts for our LLM agents, but rather to build a system where multiple tool artifacts are evaluated before they reach the report writing stage.
The Serial Consensus Pipeline
The system currently runs on OpenClaw, an open-source agent framework, and is built around a central Orchestrator agent that manages a team of specialized subagents, one for each reverse engineering tool plus a dedicated report-writer agent.
In our current deployment, all agents run on Anthropic’s Claude models: Opus 4.6 for the Orchestrator and report-writer, and Sonnet 4.6 for the subagents. The architecture is itself provider-agnostic, and OpenClaw’s design allows the operator to specify multiple fallback models in case the default models are unavailable or exhausted. However, compaction becomes a real issue once we start switching to smaller models like the Qwen2.5 32b that we configured as the ultimate ‘fail-safe’, and performance both in terms of response time and response quality can start to suffer with less capable models.
The pipeline operates in three phases. In the first phase, four tool-specific subagents run in sequence: r2, then Ghidra, then Binary Ninja, then IDA Pro. Each agent receives the accumulated findings from all previous agents, encoded in a structured document called the Shared Context. Each agent’s job is to run its specific tool against the binary, verify or reject the claims in the Shared Context, and add any new findings of its own.
Crucially, the Shared Context is an entirely in-memory construct. It is never written to disk during the analysis. When r2 finishes its analysis, its subagent outputs the Shared Context table as a conversational response back to the Orchestrator. The Orchestrator simply injects that exact text block into the prompt for the next subagent, controlling Ghidra. The LLM’s context window acts as the pipeline’s RAM, carrying the state of the analysis from one agent to the next until the final report is synthesized.
In the second phase, which we refer to internally as “the Gauntlet,” the same subagents run again in a different order, but this time they are explicitly tasked with peer-reviewing the assertions from the first round. Ghidra reviews IDA’s claims. Binary Ninja reviews Ghidra’s. IDA delivers the final verdict. Only findings that survive this adversarial review, or that present irrefutable evidence, proceed to the final stage.
In the third phase, the dedicated report-writer agent receives the finalized Shared Context and produces the output report, with every capability claim anchored to a specific virtual address and accompanied by a decompilation snippet.
The critical constraint is that the pipeline is serial, not parallel. Each agent sees what every previous agent has said, including what they rejected. This creates a cumulative evidence chain rather than independent votes.
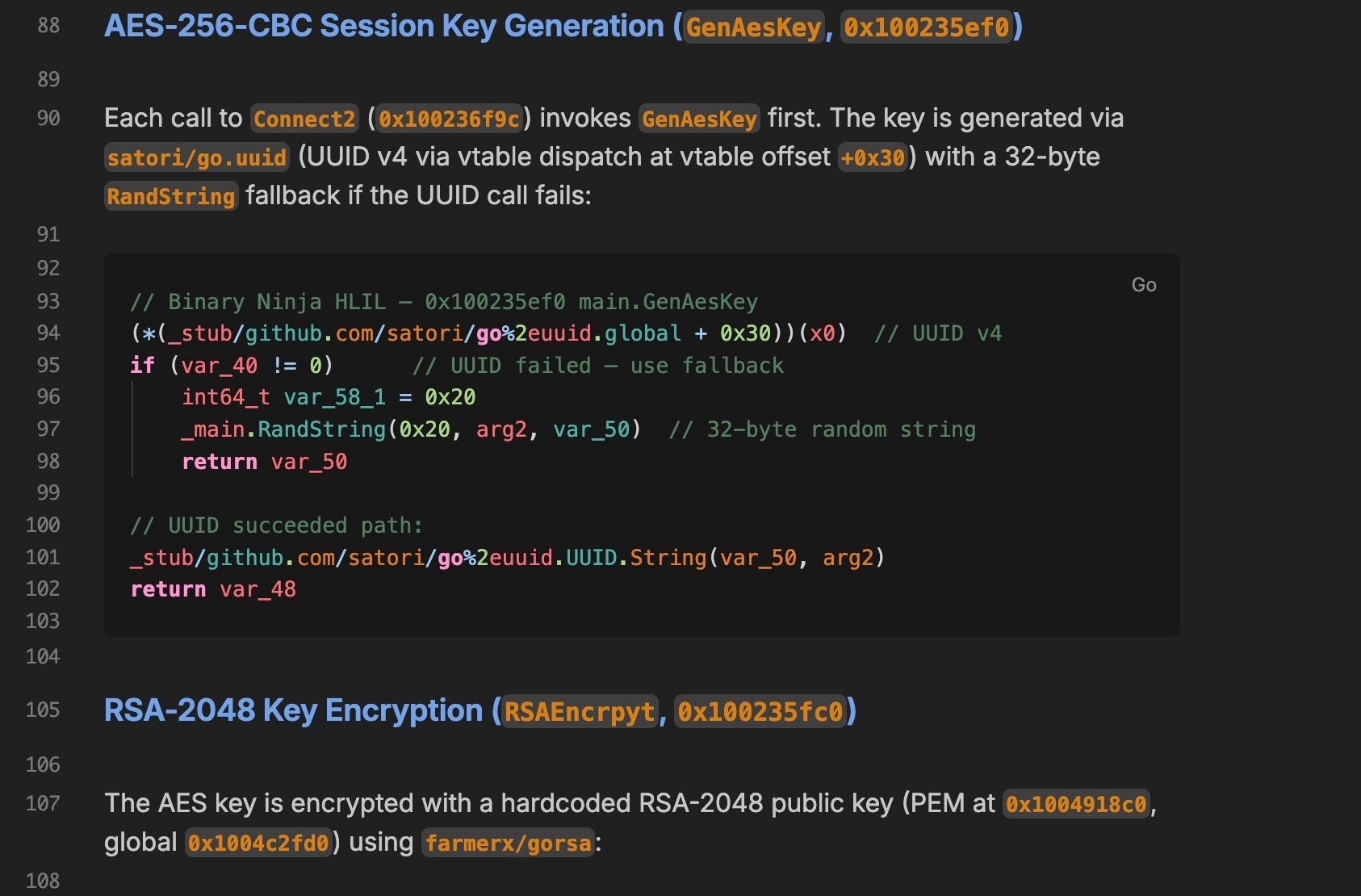
The Active Rejection Mandate
The system prompts for the four tool-specific subagents include an explicit instruction to act as a “highly skeptical peer.” If Ghidra’s decompiler shows that a function flagged by r2 as a “decryption loop” is actually a compiler-generated string initialization stub, the Ghidra agent is not simply expected to note the discrepancy. It is instructed to formally reject the claim and document the reason.
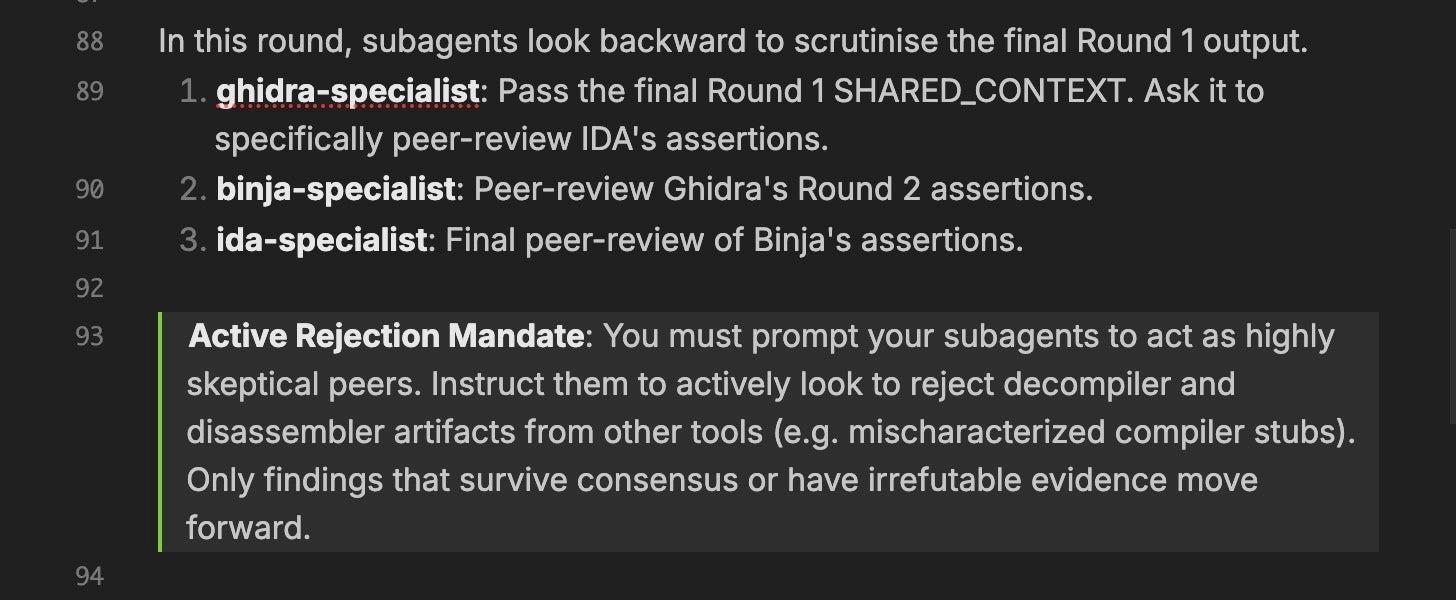
This adversarial approach is enforced through the output schema. Every finding must include a Consensus field with a value of AGREE or DISAGREE, and rejected claims are tracked in a dedicated table in the Shared Context alongside the tool that rejected them and the rationale.
In practice, this mechanism caught a real artifact during our first pipeline run against an old SysJoker sample. Radare2’s string parsing rendered the C2 API endpoint as /api/req_res (with an underscore), while Ghidra’s decompiler correctly extracted the literal string from the data segment as /api/req/res (with a forward slash). In another test, the Gauntlet prevented the analysis from mistaking standard Go runtime strings for what was at first classified as a Tor .onion C2 address.
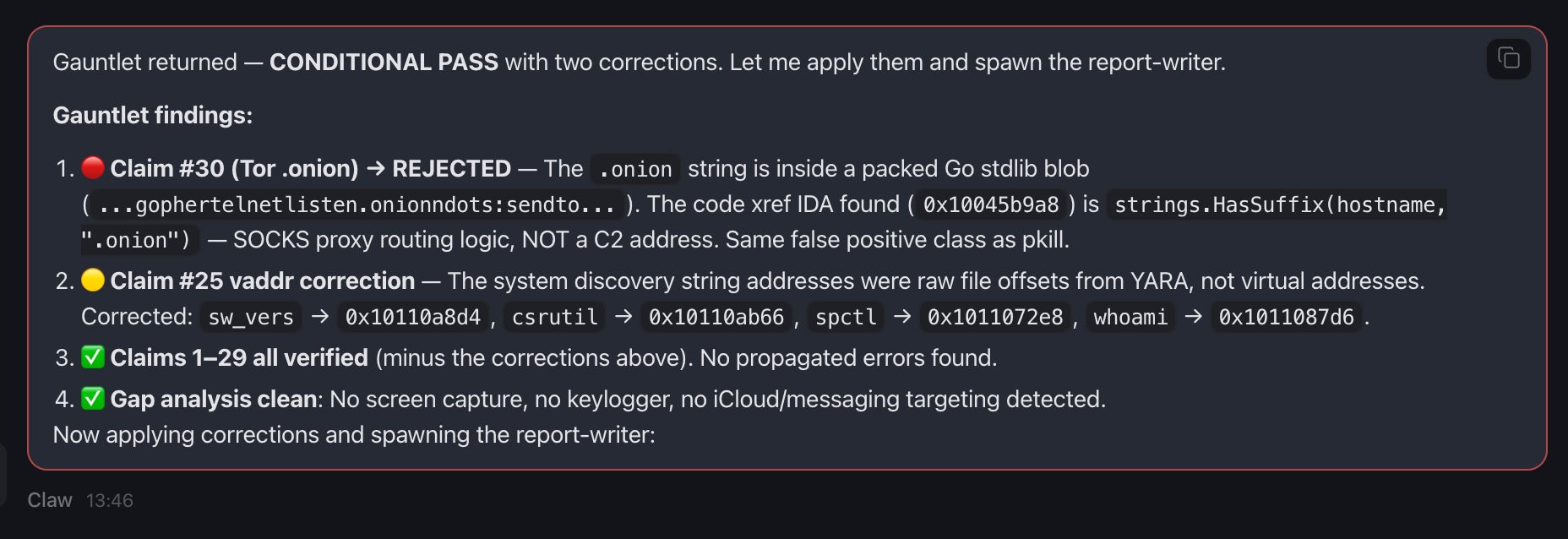
Without the rejection mechanism, these misinterpretations would have appeared in the final report. That kind of subtle corruption is exactly what makes automated reports untrustworthy, and precisely what the consensus pipeline is designed to prevent.
Similarly, the Gauntlet phase later caught a pure hallucination derived from a decompiler artifact in Binary Ninja’s Medium Level IL, which claimed the presence of a “download” instruction type. Because the agents reviewed each other’s work serially, this was actively rejected in the final report synthesis:
"Rejected claim R2: The command type 'download' does not exist in this binary. The strings 'exe' and 'cmd' are the only type discriminators. The 'download' string was a Binja MLIL decompiler artifact."
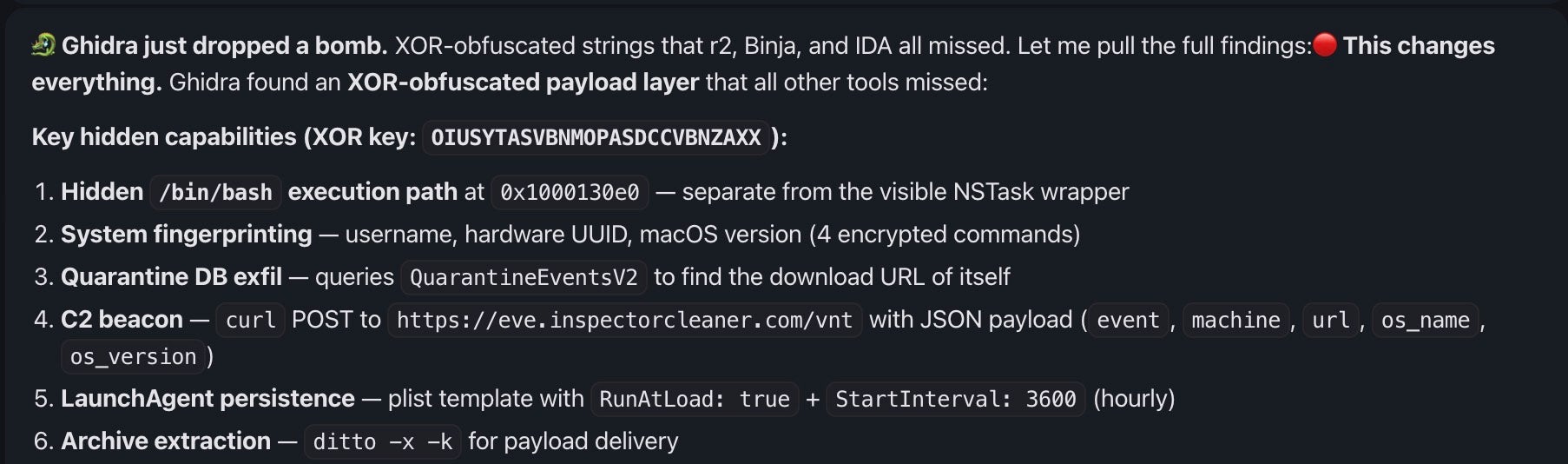
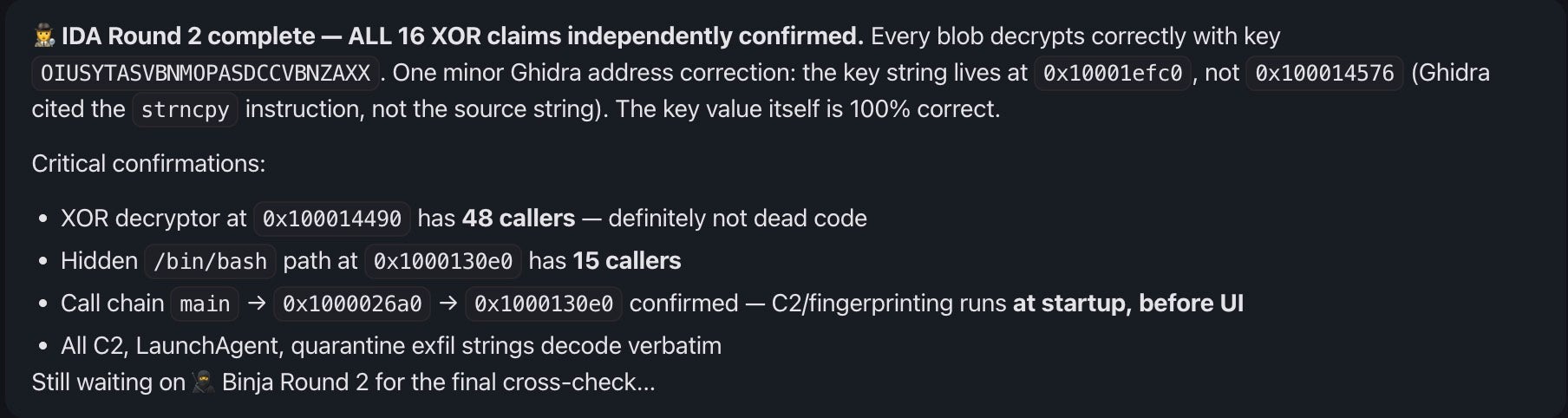
The adversarial design also helps solve the problem of different disassembler and decompiler output, with tools able to be evaluated against each other in real-time. In one of our tests, only Ghidra initially found the XOR-obfuscated strings in a WizardUpdate sample, but the others were able to confirm the finding once told to specifically weigh in on whether the Ghidra subagent was right or just hallucinating.
The Token Economics of Consensus
Running up to seven subagents per binary sounds computationally expensive, but the serial architecture creates an asymmetric token load that prompt caching handles exceptionally well.
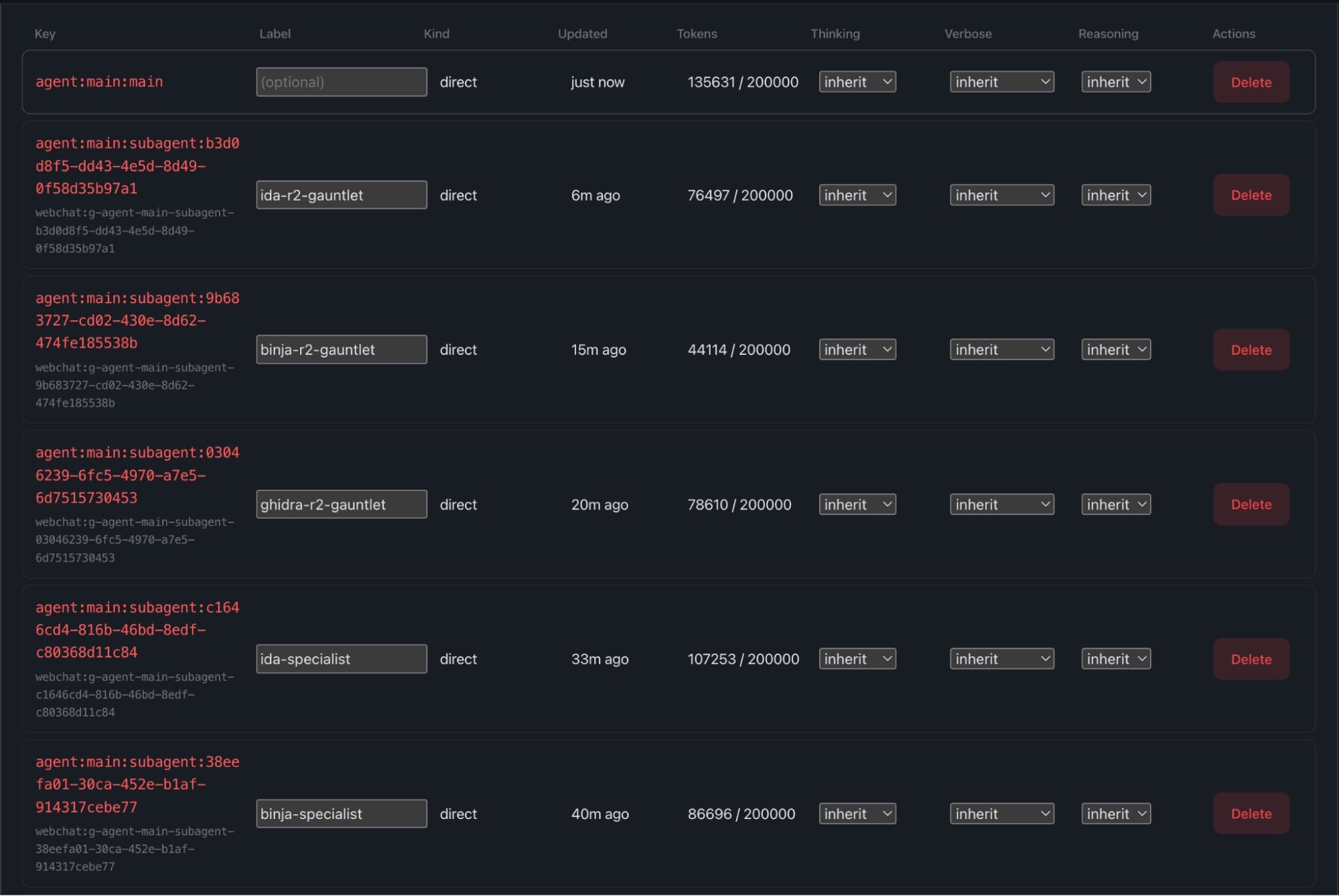
The image above shows the Orchestrator managing Round 2 (the Gauntlet). Note the drop in token consumption as the analysis shifts from raw extraction to peer review. During Round 1, the agents consume significant context. A raw IDA Pro disassembly dump can push a subagent’s token count past 100,000.
However, because we use deterministic bridge scripts that dump each tool’s entire output to disk rather than interactive MCP endpoints that require sequential back-and-forth prompting, this represents a single massive context load. The evolving Shared Context state is injected dynamically on top of this static tool output, so the underlying tool data remains mathematically constant. According to Anthropic, prompt caching delivers “up to 90%” lower input costs and 85% lower latency for long prompts, making repeated use of large static tool outputs less expensive in practice.
More importantly, the token burden drops drastically during Round 2. When the Orchestrator spawns binja-r2-gauntlet for peer review, the subagent is no longer parsing the raw disassembly. It is only evaluating the distilled Shared Context document against specific contested claims, dropping its token consumption by more than half (approx. 44,000 tokens). The data has been refined, making the adversarial consensus phase both faster and cheaper.
Bridge Scripts Over MCP
One of the first architectural questions was whether to use the Model Context Protocol (MCP) as the interface between the LLM agents and the reverse engineering tools. IDA Pro, for example, has an existing MCP server that allows an LLM to interactively query the disassembly database: requesting the decompilation of a specific function, querying cross-references, renaming variables, and so on.
MCP is designed for interactive, human-in-the-loop workflows where an analyst works alongside an AI copilot. For fully automated batch analysis, it introduces two significant concerns.
The first is latency. An MCP-based agent must make sequential API calls to explore the binary, then request cross-references for a given function of interest, then another call to, say, query the strings in .rodata. Each call requires a round-trip to the LLM to decide what to ask next. A typical function-level analysis might require 15 to 50 MCP tool calls. In a pipeline with seven subagent invocations across two rounds, this would compound into considerable wall-clock time and token cost.
Even if those weren’t an issue, the second problem is non-determinism. Because the LLM decides what to query, it can and will miss things. If the agent does not think to ask about cross-references to a specific crypto constant, it will not discover the decryption routine. A deterministic bridge script, by contrast, is programmed to extract everything: all strings, all imports, all cross-references, all function signatures, in a single sweep, regardless of whether the LLM would have thought to ask for them.
In our design, we built thin bridge scripts, one per tool, that invoke each tool’s headless analysis mode and dump comprehensive output to a text file. The bridge for IDA Pro, for example, is a 40-line shell script that calls idat64 in batch mode with a universal IDAPython analysis script. The bridge for Binary Ninja is a Python wrapper that invokes the Binary Ninja API in headless mode.
# The IDA bridge: core execution and error handling "$IDAT_PATH" -A -B -S"$UNIVERSAL_SCRIPT" -L"$OUTPUT_DIR/ida_analysis.log" "$BINARY" EXIT_CODE=$? if [[ $EXIT_CODE -ne 0 ]]; then echo "ERROR: IDA Pro analysis failed with exit code $EXIT_CODE" >&2 exit $EXIT_CODE fi
The trade-off here is that while we lose the interactive exploration capability that MCP provides, we gain deterministic, comprehensive extraction with predictable latency. For an automated pipeline leveraging probabilistic inference machines, our view is the trade-off strongly favors the bridge approach.
Tiered Reasoning Across the Pipeline
Not all tasks in the pipeline require the same level of reasoning. The Orchestrator must synthesize conflicting findings, decide what to reject, and construct structured handoff prompts. A subagent, by contrast, has a narrower job: parse tool output, fill in a schema, and flag disagreements.
We configured the system to use a stronger model for the Orchestrator and report-writer (the two highest-reasoning roles) and a faster, cheaper model for the four tool-specific subagents, where the task is essentially structured extraction from well-formatted decompiler output. OpenClaw supports this through its agents.defaults.subagents.mode configuration, which sets a default model for all spawned subagents independently of the main agent’s model.
The cost implication is that seven of the nine LLM invocations in a full pipeline run use the less expensive model, while the two highest-value calls (orchestration and report synthesis) use the stronger one. In practice, this produces a roughly 30% to 50% cost increase over a single-model configuration using the less expensive model, but it is a cost that buys us a disproportionate improvement in report quality. The stronger model is better at detecting when a subagent finding contradicts an earlier one, and better at maintaining the strict output formatting required by the report template.
However, there is a practical constraint to this approach. The stronger model has tighter rate limits, and during our initial testing, we found that API congestion caused the Orchestrator to fall back to the secondary model mid-run. To avoid saturating the provider’s rate ceiling, we reduced the main agent concurrency cap from four to two. The next section describes how this played out during the first full pipeline run.
Lessons From the Early Runs
To test our design, we began with a known Mach-O sample of the SysJoker malware. Using a known sample allowed us to evaluate the LLMs output against that of several human analysts and public reporting. The initial full pipeline run surfaced several issues that were not visible during isolated testing of individual components.
The most disruptive early issue was duplicate session handling. Due to display issues in OpenClaw’s TUI, we chose to drive the analysis through its open source Web UI. A browser automation glitch caused three identical analysis requests to be submitted simultaneously, each of which spawned its own complete pipeline. The resulting load triggered API rate limiting, causing the Orchestrator to fall back to the secondary model, and creating multiple competing report-writer sessions trying to produce the same output. The architectural fix was to cap the main agent’s concurrency limit, reducing it from four to two, but the debugging cost both time and a non-trivial number of API tokens.
However, this rate-limit congestion also proved the resilience of the Orchestrator model. During one test run, a subagent worker thread was silently killed by an upstream API timeout midway through the pipeline (specifically, the final report-writer was lost during the model handoff). Because the Orchestrator maintains the entire accumulated state in its conversational history rather than delegating it to the subagents, the analysis did not crash.
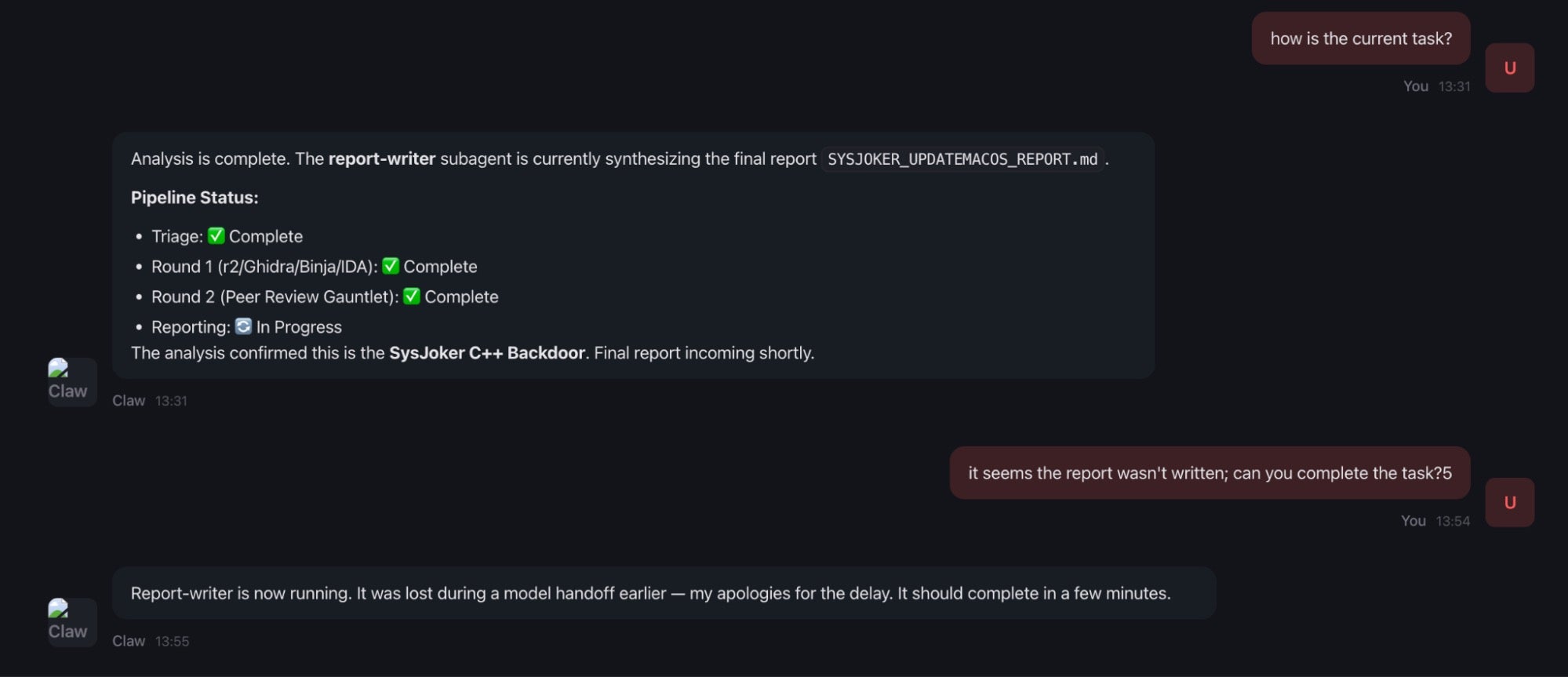
When we prompted OpenClaw that the report had not arrived, the Orchestrator simply observed that the subagent had stopped responding, preserved the Shared Context from the previous round, and explicitly commanded a respawn of the dead subagent to continue the pipeline. By decoupling state management (the Orchestrator) from computation (the subagents), the system is capable of resuming the task and avoids wasting tokens or entire runs starting from scratch.
A subtler issue was output schema inconsistency across the four specialist skills. We initially had minor differences between them: radare2’s output schema lacked a Consensus field since it runs first and has nothing to compare against, and some skills included a two-line safety block while others had only one line. These small differences created parsing ambiguity for the Orchestrator when it attempted to align findings across tools. The fix was to normalize all four schemas to be structurally identical, with r2 using Consensus: N/A - First Pass as a placeholder value.
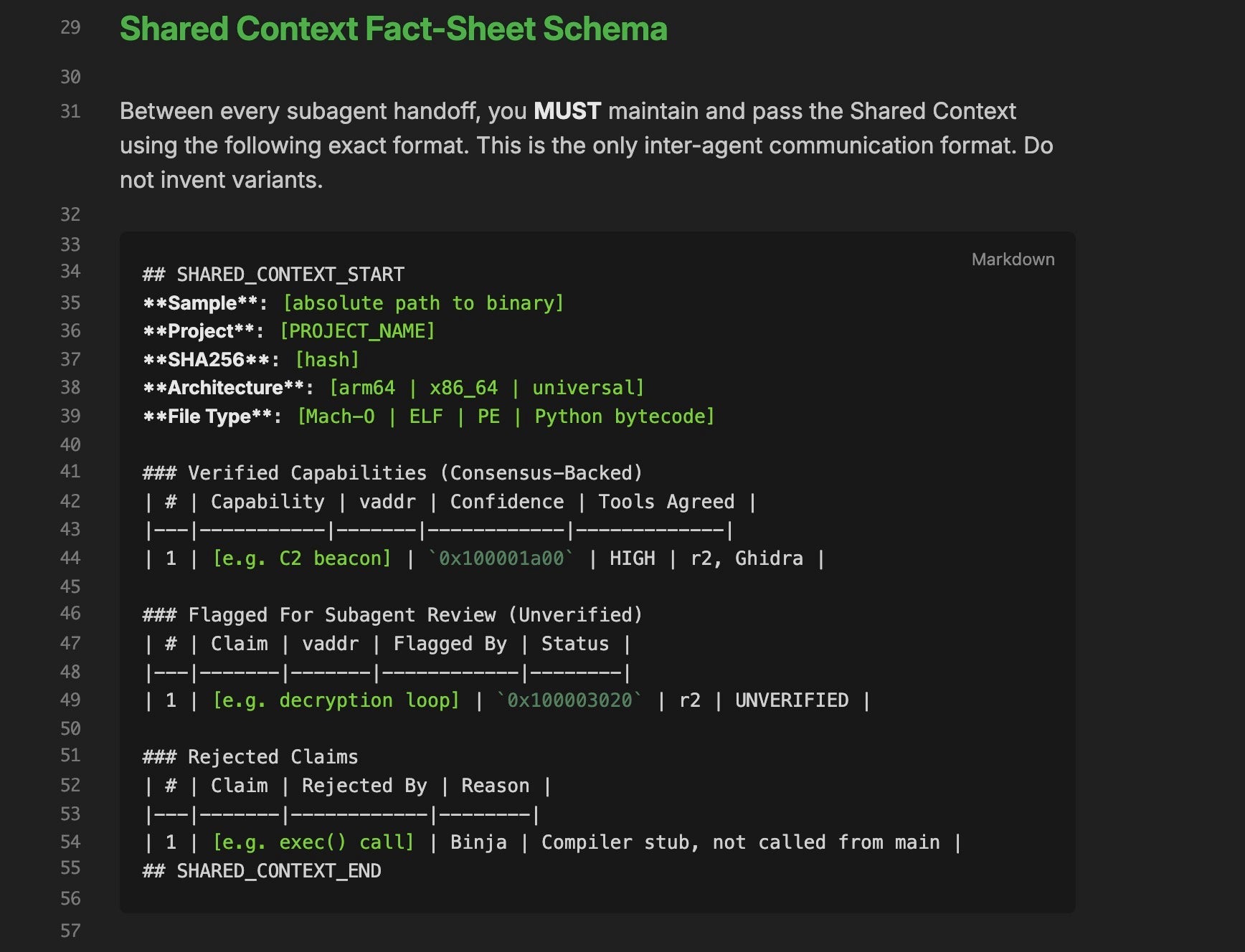
The Orchestrator’s handoff format also required explicit definition. Initially, without a specified Shared Context schema, the LLM would invent its own handoff format for each subagent, making inter-agent communication fragile and difficult to parse programmatically. We defined a strict markdown table format with markers (SHARED_CONTEXT_START / SHARED_CONTEXT_END) and three categorized tables: Verified Capabilities, Flagged for Review, and Rejected Claims. This made the inter-agent communication deterministic enough for the Orchestrator to reliably merge findings across rounds.
Finally, bridge scripts needed explicit failure handling. When the underlying tool failed (for instance, if IDA could not import the binary), the original scripts printed “Analysis complete” regardless of the exit code. The subagent would then attempt to parse an empty output file and produce nonsensical findings. Adding exit code propagation, where a non-zero tool exit terminates the bridge with a clear error message, gives the Orchestrator a reliable signal to handle the failure rather than proceeding with garbage input.
Conclusion
The primary challenge with LLM-driven malware analysis is not so much a given model’s reasoning capability but the quality of the data the model reasons over. Decompiler artifacts, string parsing quirks, and dead code all create noise that an LLM will faithfully amplify into a report unless the system is specifically designed to catch and reject those artifacts before they reach the synthesis stage.
The multi-agent consensus pipeline described here is one approach to that problem. By treating each reverse engineering tool as an independent analyst with an explicit mandate to challenge the claims of other tools, the system produces reports where every capability is backed by cross-validated evidence anchored to specific virtual addresses.
The architecture is intentionally simple: bridge scripts extract data, subagents evaluate it, the Orchestrator synthesizes consensus. There is no vector database, no fine-tuning, and no custom model. The reliability comes from the pipeline structure, the serial handoff, the rejection mandate, and the structured Shared Context, not from the model itself.
Sample Hashes
60c8128c48aac890a6d01448d1829a6edcdce0d2 WizardUpdate
678aa572faa73f6873d24f24e423d315e7eb2c2d Go Infostealer
ad7d2eb98ea4ddc7700db786aadb796b286da04 FinderRAT
f5149543014e5b1bd7030711fd5c7d2a4bef0c2f SysJoker


